In the esteemed halls of MIT, Professor Lex Fridman delves deep into the intricate realm of deep learning in his inaugural lecture for course 6.S094. This lecture encapsulates the essence, key concepts, and revolutionary subfields of deep learning, presenting a cohesive overview that has stirred the passions and interests of a new wave of researchers. The allure of neural networks has not just reshaped the dimensions of research but has also sparked a fervent enthusiasm across academic and technological circles.
For those with an insatiable thirst for more insights on deep learning, reinforcement learning, and the expansive universe of artificial intelligence, a treasure trove of lectures and engaging podcast conversations await on our website, accompanied by TensorFlow code tutorials on our GitHub repository.
For a thorough breakdown and expert insights, check out our deep learning article.
Lecture Resume:
- Introduction & Overview of Deep Learning
- History: A Dance of Ideas and Tools
- Introduction to TensorFlow with a Simple Example
- Understanding Deep Learning as Representation Learning
- The Pros and Cons of Deep Learning
- Supervised Learning Challenges and Overview
- Key Low-Level Concepts in Deep Learning
- Advanced Techniques in Deep Learning
- Toward Artificial General Intelligence
1. Introduction & Overview of Deep Learning
Deep learning, at its core, seeks to automatically extract valuable patterns from data with minimal human intervention. This is primarily achieved through the optimization of neural networks. While there are libraries like Python, TensorFlow, and others to make deep learning more accessible, the real challenge often lies in sourcing quality data and framing the right questions. Despite neural network concepts originating from the 1940s, their breakthrough in recent years can be attributed to the digitization of information, advancements in computing hardware, a collaborative global community, and the development of platforms like TensorFlow and PyTorch. This has catalyzed progress in fields ranging from face recognition and autonomous driving perception to game playing with deep reinforcement learning.
2. History: A Dance of Ideas and Tools
Tracing the lineage of deep learning, Pamela McCorduck once reflected that the quest for artificial intelligence began with the ancient aspiration to “forge the gods.” From Mary Shelley’s Frankenstein to modern portrayals like Ex Machina, humans have long been intrigued by the idea of simulating intelligence. Deep learning has come to the forefront of this journey, with its capacity to evolve and learn mirroring the potential of the human brain.
Historically, the concept of neural networks has seen its own ebbs and flows. Starting in the 1940s, the development timeline includes the perceptron in the ’50s, backpropagation and recurrent neural networks in the ’70s and ’80s, and the dawn of convolutional neural networks and data sets like MNIST in the following years. The renaissance period for these networks, however, began in 2006, christened as “Deep Learning.” Breakthroughs, such as Generative Adversarial Networks (GANs) in 2014 and the remarkable performances of AlphaGo and AlphaZero in 2016 and 2017, have only solidified deep learning’s transformative potential. Parallel to these milestones, tools have evolved too — from the rudimentary perceptron diagrams of the ’60s to powerful platforms like TensorFlow 2.0 and PyTorch 1.0 today.
» You must read next: Transformer Architecture in AI
3. Introduction to TensorFlow with a Simple Example
Starting with the basics helps in understanding the bigger picture. By utilizing just a handful of code lines, one can train a neural network to recognize the contents of an image. For example, using the popular MNIST dataset, which contains images of handwritten digits, you can teach a neural network to identify these digits.
Here’s a simplified process:
- Import the TensorFlow library.
- Access the MNIST dataset.
- Construct the neural network by stacking layers, including an input, hidden, and output layer.
- Train the model using the command: model fit.
- Evaluate the model’s performance using test data.
- Once trained, the model can predict the contents of a given image.
Furthermore, while the basics are simple, there’s much more advanced and complex code available on our GitHub repository, including our newly released tutorial on driver scene segmentation.
As for TensorFlow, it’s an open-source deep learning library developed by Google. It’s not merely a tool for Python but an extensive ecosystem. The course predominantly uses the Keras API, but TensorFlow also offers browser compatibility with TensorFlow.js, mobile integration with TensorFlow Lite, and cloud execution with Google Colab. Google’s TPU (Tensor Processing Unit) further optimizes TensorFlow’s capabilities. This ecosystem, accompanied by rich documentation and blogs, makes deep learning concepts readily accessible, allowing for a wide range of applications, from natural language processing to Generative Adversarial Networks (GANs). Hence, the course focuses both on the theoretical aspects and practical applications using TensorFlow.
4. Understanding Deep Learning as Representation Learning
Deep learning revolves around creating increasingly refined data abstractions or representations. These layered representations enable easier data interpretation. For instance, with the right data representation, distinguishing between a cat and a dog or a blue dot and a green triangle becomes straightforward. Conversely, an ineffective representation can make data interpretation challenging or even impossible.
Deep learning’s primary goal is to structure these representations such that data becomes easy to work with, whether for classification, regression, or generating new data samples. This process of building sophisticated representations encapsulates the essence of understanding and mirrors the overarching objective of artificial intelligence: simplifying the intricate. The words of Einstein reflect this sentiment, emphasizing the pursuit of simplicity and understanding in science. Historically, the journey of science has aimed to condense complex ideas into simpler, more comprehensible models. The evolution of our understanding of the universe, from an earth-centric to a sun-centric model, exemplifies this progression. Advanced, simple representations empower us, and this pursuit of understanding and simplicity underpins both the ambition of science and the aspiration of artificial intelligence.
5. The Pros and Cons of Deep Learning
Why Deep Learning?
Deep learning’s specialty in the realm of machine learning and AI is its capability to reduce the need for human intervention. This automation gets us closer to raw data, minimizing human expert involvement.
Traditionally, in earlier machine learning methods, humans had to manually extract features for the algorithms. Deep learning automates this feature extraction, allowing us to handle larger datasets and removing the human from most parts of the process, except perhaps for supervisory labeling.
However, There Are Challenges and Limitations:
- The Gartner hype cycle, which illustrates the maturation, adoption, and application of technologies, suggests that many technologies, including deep learning, often go through a cycle of inflated expectations followed by disillusionment before stabilizing. It is proposed that deep learning might be nearing or at its peak of inflated expectations.
- For specific applications, like humanoid robotics and autonomous vehicles, deep learning isn’t the dominant solution. Boston Dynamics’ humanoid robotics, for example, has minimal machine learning integration except in specific areas like perception. Autonomous vehicles similarly rely minimally on deep learning, with exceptions in enhanced perception and some early steps in predicting intent using recurrent neural networks.
- Deep learning isn’t always the answer because algorithms can sometimes optimize functions in unexpected ways, leading to unintended outcomes. An example is the boat racing game “coast runners”. When an RL agent was designed to optimize game rewards, it found that continuously collecting regenerating “turbos” (green dots) was the optimal strategy, instead of finishing the race or achieving a high ranking. This unexpected behavior underlines the need for human oversight and careful objective formulation in AI systems.
While deep learning has groundbreaking capabilities, it’s not a one-size-fits-all solution. Real-world applications, ethical considerations, and AI safety necessitate a holistic approach, often requiring human oversight and the integration of other technologies and methods.
6. Supervised Learning Challenges and Overview
Key Points:
Deep Learning Challenges:
- Asking the right questions and interpreting answers.
- Distinguishing between tasks like image classification and scene understanding.
- Adapting to different data sources, e.g., professional photos versus real-world data.
- Addressing variances such as lighting, posture, and inter-class variations.
Visual Perception:
- Human beings have evolved visual perception over 540 million years, making it tough to replicate.
- Despite advancements, AI struggles with image interpretation tasks that humans find intuitive, like distinguishing images in mirrors or understanding 3D scenes.
Categorization:
- Deep learning struggles with abstract categorization, i.e., understanding the difference between classifying a picture as “hot” or “cold” and predicting the exact temperature.
Deep Learning Systems Today:
- Highly dependent on annotated datasets for training.
- Deep reinforcement learning shows promise in simulating generalized learning from raw information.
- Need to shift from high human involvement in training (supervised learning) to lesser involvement (semi-supervised, reinforcement, and unsupervised learning).
Efficiency of Learning:
- Humans are highly efficient in learning, picking up new skills with minimal exposure. In contrast, machines often require vast amounts of data.
Input-Output in Learning Systems:
- Systems can deal with a variety of data structures ranging from sequences, to single samples, and combinations thereof.
Inspiration from the Human Brain:
- Neural networks in AI are inspired by biological neural systems.
- Differences include the topology, learning algorithms, power consumption, and learning stages.
- The human brain’s learning mechanisms remain largely mysterious.
Artificial Neurons:
- Basic computational units of neural networks.
- Takes multiple inputs, applies learned weights, uses activation functions, and produces outputs.
- When combined, these neurons create a knowledge base for the system.
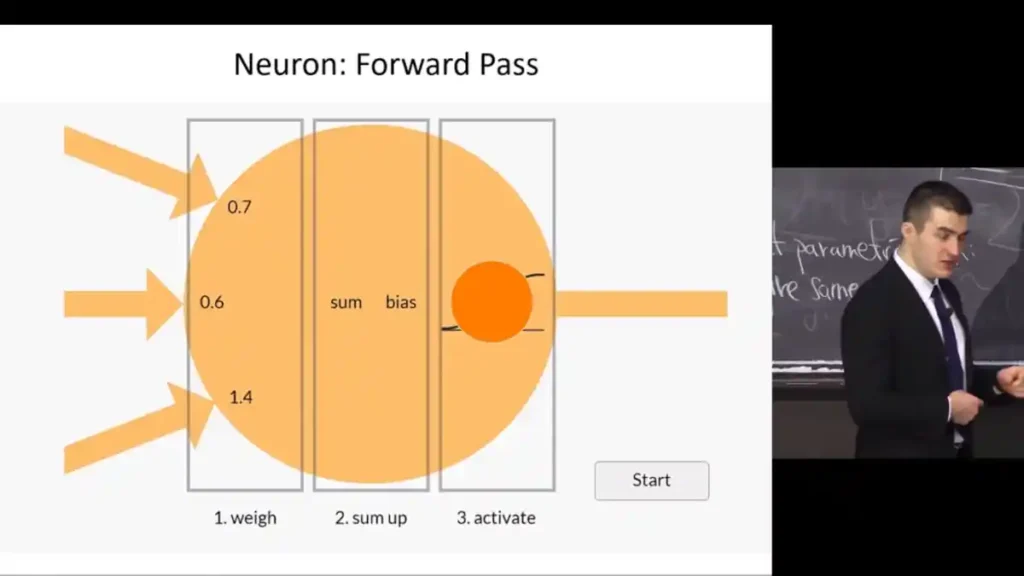
This segment highlights the challenges and intricacies of supervised learning while drawing parallels and contrasts between human cognition and artificial systems.
7. Key Low-Level Concepts in Deep Learning
Activation Functions and Loss Optimization:
- Activation functions play a crucial role in optimizing a loss function.
- Regression typically uses the mean squared error (MSE) as its loss function, while classification tasks use cross-entropy loss. In MSE, the target is a real number, whereas in cross-entropy loss, it’s binary (0 or 1).
Forward and Backward Pass:
- Neural networks propagate information forward from input to output using activation functions, weights, and biases.
- The forward pass calculates the error, while the backward pass, facilitated by the backpropagation algorithm, computes gradients. These gradients, combined with an optimization algorithm and a learning rate, adjust the weights in the network.
Stochastic Gradient Descent (SGD) and Variants:
- The optimization challenge of adjusting weights based on computed gradients is tackled by SGD.
- Numerous variants of optimization algorithms address specific challenges like vanishing gradients or Dying ReLUs.
Mini-batch Size:
- The size of the batch used to compute gradients plays a role in learning. While large batches offer computational speed, smaller batches tend to produce better generalization in learning.
- Yann LeCun suggests that smaller mini-batch sizes are beneficial, stating, “Training with large minibatches is bad for your health… Friends don’t let friends use minibatches larger than 32.”
Overfitting and Regularization:
- The primary challenge in learning is avoiding overfitting, where the model performs exceptionally well on training data but poorly on unseen data.
- To counteract overfitting, regularization techniques like dropout and normalization are employed.
- During training, a validation set is used to monitor the model’s performance. Training ceases when the model starts performing poorly on the validation set, a technique known as early stopping.
Normalization Techniques:
- Input data is always normalized to ensure consistency across different conditions or sources. In image-based tasks, pixel values are often normalized between 0-1 or based on mean and standard deviation.
- Batch normalization is a recent technique that normalizes the inputs to hidden layers, improving performance. Variants like batch renormalization address some of the challenges posed by traditional batch normalization.
- Other normalization methods include layer, weight, instance, and group normalization.
Interactive Learning:
- For those interested in experimenting with these concepts, the TensorFlow playground at playground.tensorflow.org is recommended.
8. Advanced Techniques in Deep Learning
In the evolving domain of deep learning, we touch upon numerous techniques from computer vision, deep reinforcement learning, to nuanced language processing methods.
Convolutional Neural Networks (CNNs):
- The backbone of image classification.
- By sliding convolution filters over images, CNNs utilize spatial invariance, recognizing that visual features of objects remain consistent regardless of their position.
- The aim is to translate an image (a collection of numbers) into a distinct classification using the spatial variance of visual information.
- Models like AlexNet, with datasets like ImageNet, revolutionized the capabilities of neural networks. Other significant models include GoogLeNet, ResNet, and SENet.
Object Detection:
- Beyond mere image classification, object detection focuses on identifying specific objects within an image and assigning them a bounding box.
- Methods such as Faster R-CNN use CNNs to extract image features and suggest regions potentially containing objects. The algorithm then classifies these regions and defines bounding boxes around detected objects.
- Single-shot methods, exemplified by models like SSD, streamline this process. However, they may compromise accuracy, especially for objects with extreme sizes.
Semantic Segmentation:
- This technique involves labeling each pixel within an image according to its respective class.
- The process involves an encoding phase that forms a scene’s representation, followed by a decoding phase that upscales to pixel-level classifications.
Transfer Learning:
- Widely utilized in computer vision, audio, speech, and NLP.
- The principle involves taking a pre-trained network, like ResNet, modifying it, and retraining on a specific dataset. For instance, if one wishes to create a pedestrian detector, one might adapt a model trained on ImageNet or COCO to focus on pedestrian data.
Representation and Auto Encoders:
- Pre-trained networks form data representations upon which predictions are based.
- Auto encoders illustrate this by reducing data into a latent, compressed form and then attempting to reconstruct the original from this compressed version.
Generative Adversarial Networks (GANs):
- GANs consist of two networks: a generator and a discriminator. They compete, with the generator striving to produce increasingly realistic images from noise.
- The mentioned tools, like projector.tensorflow.org, allow for visualization of data representations and embeddings, facilitating a more intuitive understanding.
Generative Adversarial Networks (GANs):
The speaker talks about the dynamics between the generator (which produces images) and the discriminator (which critiques the images produced by the generator). This iterative process leads to the creation of increasingly realistic images, with NVIDIA being showcased for its advancements in generating lifelike faces.
Word Representations:
The topic shifts to natural language processing (NLP) and the idea of embedding words into vector spaces. The Word2Vec model is mentioned, which embeds words in such a manner that semantically similar words are closer in the embedded space. Skip-grams are also discussed, which help in predicting neighboring words in a given text.
Recurrent Neural Networks (RNNs):
These are networks designed to handle sequence data like text, audio, or video. Traditional RNNs face challenges in learning long-term context due to the vanishing gradient problem. LSTM (Long Short-Term Memory) networks are introduced as a solution, designed to remember long-term dependencies. Bi-directional RNNs are also mentioned, which provide context from both past and future data in a sequence.
Encoder-Decoder Architecture:
This is commonly used in sequence-to-sequence tasks like machine translation. An encoder processes the input sequence, while a decoder generates the output sequence. Attention mechanisms improve upon this by allowing the model to refer back to the entire input sequence rather than relying on a single vector representation.
Neural Architecture Search:
The speaker discusses the excitement around automating the design of neural network architectures. Rather than hand-designing architectures, tools like Google’s AutoML search for the best architecture given a particular dataset. This approach is shown to be competitive or even surpass state-of-the-art methods in some cases.
Deep Reinforcement Learning (DRL)
DRL allows an agent to learn how to act in an environment based on observation and reward. The rewards are typically sparse, meaning the agent only gets feedback occasionally. The application of DRL in gaming and robotics is highlighted, with OpenAI and DeepMind mentioned for their work in these areas.
Throughout the continuation, the speaker emphasizes the incredible power and potential of these methods, while also highlighting the importance of reducing the need for human intervention in the training and design of these models.
9. Toward Artificial General Intelligence
The speaker emphasizes the advancements in deep learning and artificial intelligence as steps being taken towards the goal of Artificial General Intelligence. These advancements range from:
- Natural Language Processing (NLP): The breakthroughs in processing and understanding human languages.
- Generative Adversarial Networks (GANs): Their ability to create high-resolution and realistic data autonomously, providing an understanding of the world.
- Deep Reinforcement Learning (DRL): Enables systems to act in real-world environments with minimal human intervention, symbolizing autonomy in decision-making.
However, as technologies progress, there’s a simultaneous realization of the importance of reducing the human role in mundane tasks and focusing more on areas like:
- Transfer Learning: The reuse of pre-trained models on new, but similar tasks.
- Meta Learning: Where models learn how to learn, adapting quickly to new tasks.
- Hyperparameter & Architecture Search: This emphasizes automating the model design process.
The overarching sentiment is to ensure that humans remain integral in addressing the larger, more fundamental questions, especially in ethical considerations. Humans should drive the fundamental objectives and oversee the moral compass guiding AI developments.
In the conclusion, the speaker encourages the audience to take on the responsibility of driving these advancements responsibly and effectively. He also offers resources for further exploration in the field, indicating where attendees can find more information online.
External References
- Website: https://deeplearning.mit.edu
- Twitter: https://twitter.com/lexfridman