In today’s interconnected world, system availability is not just a desirable feature; it’s a critical necessity. Enter “Failover,” a safeguard mechanism that ensures your services remain up and running, even when primary systems falter. In this article, we will delve into the inner workings of failover systems, demystify its types, and evaluate its implementation in various environments. Buckle up, as we navigate this key survival mechanism that keeps the digital world ticking.
In this article:
- What is Failover?
- Types of Failover
- Failover Clustering
- Load Balancing and Failover
- Failover in Databases
- Failover in Cloud Computing
- Network Failover Strategies
- Monitoring and Management
- Case Studies
- Conclusion
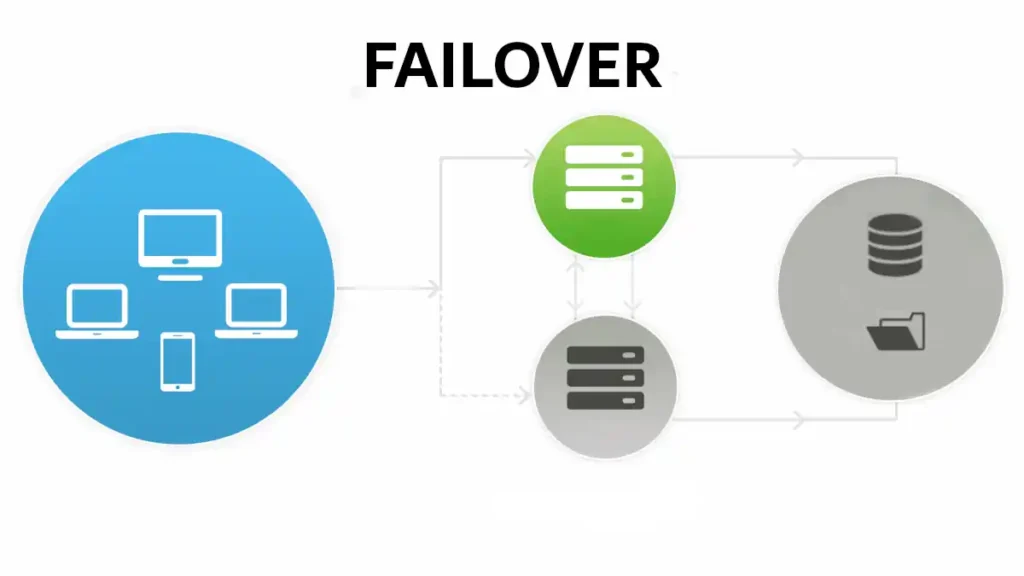
1. What is Failover?
Failover is the seamless, often automatic, switching from a failing system to a backup or secondary system. In essence, it acts as a safety net, ensuring uninterrupted service when the primary system is compromised. Now, let’s dive deeper into why failover is not merely an option but a critical need. Systems that support financial transactions, healthcare records, or critical infrastructure, cannot afford to be down, not even for a few minutes. The cost of downtime can range from lost revenue to damaged reputations and, in extreme cases, can even endanger lives.
Primary vs. Secondary Systems
In a failover configuration, there are generally two key players: the primary system and the secondary (or backup) system. The primary system is your main workhorse, handling all the tasks until it encounters an issue. That’s when the secondary system steps in. To clarify, the secondary system is not a standby; it’s an equally capable entity, prepped and ready to take over at a moment’s notice.
2. Types of Failover
Active-Passive
In an Active-Passive setup, the primary system handles all the tasks while the secondary system remains idle, waiting for its turn to shine. Once the primary system fails, the secondary system takes over, and service continues without a hitch. It’s a straightforward yet effective model that’s particularly popular in database and server environments.
Active-Active
Contrary to Active-Passive, in an Active-Active configuration, both systems are operational and share the workload. If one fails, the other immediately picks up the full load, ensuring zero downtime. This approach is often used in load-balanced environments and offers the benefit of utilizing all available resources rather than keeping one system idle.
Manual vs. Automatic
The process of switching from the primary to the secondary system can either be manual or automatic. Manual failover involves human intervention, which inevitably introduces a delay in the switch. In contrast, automatic failover is almost instantaneous and is generally the preferred option for mission-critical applications where even a few seconds of downtime can be disastrous.
In summary, failover is the unsung hero that keeps our digital lives running smoothly. Whether it’s Active-Passive or Active-Active, manual or automatic, the essence remains the same: to provide a seamless user experience, no matter what obstacles the system may encounter. So, the next time you enjoy uninterrupted service, remember there’s a meticulously planned failover mechanism working behind the scenes.
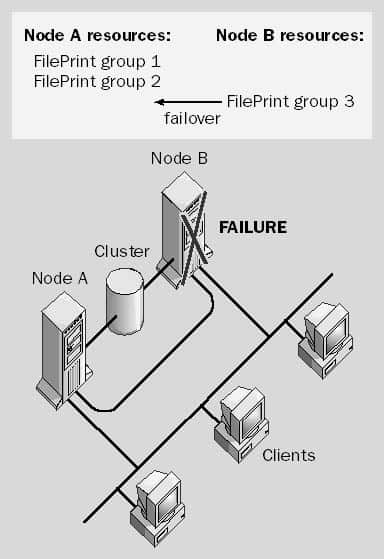
3. Failover Clustering
Windows Server Failover Clustering
When it comes to Windows environments, Windows Server Failover Clustering (WSFC) takes center stage. WSFC is a robust and sophisticated solution designed to ensure high availability for services and applications. The magic here is that WSFC keeps track of all the nodes in the cluster and, when a failure occurs, it orchestrates the transition from the failed node to a functional one. This isn’t a makeshift solution; it’s a specialized, built-in feature of the Windows Server operating system. WSFC is commonly used for services like SQL Server and Microsoft Exchange, ensuring that these mission-critical applications are always available.
See also: Failback
Linux High Availability
In the Linux world, the go-to for failover clustering is the Linux-HA project, often implemented using Corosync and Pacemaker. These tools work in tandem to monitor cluster nodes and manage resources. Linux High Availability (Linux-HA) isn’t an afterthought; it’s a feature-rich, fully-realized solution. For example, you can configure the cluster to perform automatic failback once the failed node is restored, optimizing resource usage across the cluster. Whether you’re running web servers, databases, or any other critical services, Linux-HA ensures that they remain accessible even when individual servers fail.
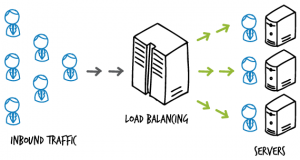
4. Load Balancing and Failover
Hardware Load Balancers
Now let’s pivot to hardware load balancers, the physical devices that distribute incoming network traffic across a number of servers. These are especially useful in an Active-Active failover configuration. When one server fails, the hardware load balancer reroutes the traffic to the remaining operational servers. It’s an effective method to achieve failover, but it comes with a significant cost implication, both in terms of hardware and maintenance.
Software Load Balancers
In contrast, software load balancers provide similar functionality but are implemented as software applications. Tools like HAProxy or NGINX serve this purpose. The key advantage of software load balancers is flexibility. Being software-based, they can easily be updated or reconfigured, often without the need for any downtime. This makes them particularly appealing for cloud-based or virtualized environments, where scalability and flexibility are key.
In essence, whether you’re in a Windows or Linux environment, whether you’re using hardware or software solutions, failover mechanisms like clustering and load balancing are pivotal to ensuring high availability. They work silently in the background, often going unnoticed until you need them the most. And when that moment comes, a well-configured failover system can be the difference between a minor hiccup and a major catastrophe.
See also: Load balancing
5. Failover in Databases
Master-Slave Replication
One of the most widely used failover strategies in databases is Master-Slave Replication. In this model, the “master” database server handles all the writes, while one or more “slave” servers are kept in sync and handle read operations. When the master server fails, one of the slave servers can be promoted to become the new master, ensuring minimal downtime. This setup is particularly useful for read-heavy applications, where slave servers can share the read load. However, the model has its challenges, such as potential data loss during failover and added complexity in keeping slave servers synchronized.
Master-Master Replication
Master-Master Replication is another failover strategy where all servers can read and write, essentially acting as masters. This can make failover almost seamless, as any server can quickly take over if another fails. The upside is improved availability and load distribution, but this comes at a cost: handling write conflicts becomes more complex. Nevertheless, if configured correctly, Master-Master Replication can offer a robust failover strategy for databases that demand high availability.
6. Failover in Cloud Computing
AWS Auto Scaling Groups
In the realm of cloud computing, AWS Auto Scaling Groups stand as a notable example of failover implementation. AWS Auto Scaling not only adjusts the number of EC2 instances to match your application’s demand but also replaces failed instances. It distributes instances across multiple availability zones to ensure that if one fails, traffic can be rerouted to another, mitigating the impact of localized failures. This offers a highly efficient, automated solution that ensures consistent application performance and availability.
Google Cloud’s Managed Instance Groups
Similarly, Google Cloud offers Managed Instance Groups (MIGs) that provide automated, scalable, high-performance, fault-tolerant service deployment. MIGs are capable of auto-healing, meaning they automatically identify and replace failed instances. Like AWS, Google Cloud’s MIGs also distribute instances across multiple zones, providing an extra layer of resilience against zone failures. With MIGs, you get the advantage of Google Cloud’s infrastructure robustness, combined with automated failover capabilities.
Both database and cloud computing environments offer failover solutions tailored to meet specific needs. Whether it’s a self-hosted database or a large-scale cloud deployment, having a failover strategy is not optional—it’s a necessity. Effective failover solutions minimize downtime, prevent data loss, and ensure high availability, making them indispensable components of any robust IT infrastructure.
7. Network Failover Strategies
DNS Failover
DNS Failover is one of the fundamental strategies to ensure high availability and fault tolerance in network setups. It functions by automatically redirecting user traffic from a failing server to a healthy one based on DNS resolution. This happens at the domain level, meaning that you can redirect traffic to completely different geographical locations if needed. The strategy offers an inexpensive yet effective way to distribute traffic and mitigate service interruptions. However, it’s crucial to consider the DNS propagation delay, which could lead to temporary unavailability.
IP Address Takeover
IP Address Takeover, or IP Failover, involves having a secondary server take over the IP address of a failing primary server. Typically, this is managed through heartbeat mechanisms that check for server health. If the primary server fails to respond, the secondary server claims the IP and begins providing the service. This strategy offers quicker failover times compared to DNS Failover but requires both servers to be on the same local network. It’s commonly used in high-availability clusters and mission-critical applications where downtime is unacceptable.
8. Monitoring and Management
Health Checks
Monitoring the health of your systems is an indispensable part of any failover strategy. Health checks are automated tests that continuously examine your systems for potential issues, like high CPU usage, low disk space, or service unavailability. By promptly detecting problems, health checks allow for quicker failover procedures, thus reducing downtime. Different platforms provide a range of health checks, from simple ping tests to more complex service-specific checks. The key is to configure these health checks accurately to reflect your system’s needs.
Log Monitoring
Logs offer a wealth of information that can aid in both identifying issues and fine-tuning your failover strategies. Log monitoring involves the continuous scrutiny of log files to spot unusual activities or errors that could indicate system issues. Modern log monitoring tools can automate this task and even trigger alerts or initiate failover procedures based on the logs. Analyzing logs is not just for troubleshooting; it’s an active measure for improving system reliability and uptime.
In sum, both network failover strategies and continuous monitoring play vital roles in ensuring high availability and fault tolerance. These measures should be tailored to your specific requirements and tested rigorously to guarantee they function as expected when the need arises.
9. Case Studies
Netflix’s Chaos Monkey
Netflix, the streaming giant, has a unique approach to ensuring failover and high availability through a tool they created called Chaos Monkey. This software intentionally introduces failures into the system during working hours to test its resilience. By “killing” services and servers randomly, Chaos Monkey forces engineers to design robust systems capable of withstanding unexpected failures. This proactive approach to failover has set a new standard in the industry, highlighting the importance of building self-healing systems that can adapt to unforeseen disruptions.
Google’s Global Load Balancing
Google employs a robust failover strategy through its Global Load Balancing service. This system distributes incoming application or network traffic across multiple servers situated in different geographical locations. When one server or entire data center goes down, the load balancer reroutes traffic to the next best server, ensuring uninterrupted service. Google’s strategy stands as a pinnacle example of how to effectively scale resources while maintaining high availability and fault tolerance.
10. Conclusion
Key Takeaways
Failover is not just an add-on but an integral part of any network or system design that aims for high availability and fault tolerance. Strategies like DNS Failover, IP Address Takeover, and cutting-edge tools like Chaos Monkey, show the varied approaches to achieving this. Monitoring and management, meanwhile, provide the backbone that supports these failover techniques, ensuring they perform optimally when needed.
Future Trends
As we move further into the era of cloud computing and distributed systems, expect to see more automated and AI-driven failover solutions. The integration of machine learning algorithms for predictive failure analysis and real-time adaptive failover mechanisms will become more prevalent. Consequently, the focus will shift from not just surviving a failure but proactively avoiding it.
In summary, failover is a complex but crucial facet of modern computing, one that will only grow in importance as our reliance on digital systems increases. Therefore, understanding its nuances and staying abreast of advancements in this field is essential for any organization aiming for resilience and reliability.