Definition of HTTP – Hypertext Transfer Protocol in Network Encyclopedia.
What is Hypertext Transfer Protocol?
Hypertext Transfer Protocol is a standard Internet protocol that specifies the client/server interaction processes between Web browsers such as Microsoft Internet Explorer or Chrome and Web servers such as Microsoft Internet Information Services (IIS) or Apache. HTTP follows a classical client-server model, with a client opening a connection to make a request, and then waiting until it receives a response.

Contents (this page)
- How Hypertext Transfer Protocol works
- HTTP Headers
- HTTP Request Methods
- HTTP Status Response Codes
- Hypertext Transfer Protocol Caching (making webpages faster)
- HTTP Messages
- History and Evolution of Hypertext Transfer Protocol
- Web references
How it works
The original Hypertext Transfer Protocol (HTTP) 1.0 protocol is a stateless protocol whereby a Web browser forms a connection with a Web server, downloads the appropriate file and then terminates the connection.
The browser usually requests a file using an HTTP GET method request on TCP port 80, which consists of a series of HTTP request headers that define the transaction method (GET, POST, HEAD, and so on) and indicates to the server the capabilities of the client. The server responds with a series of HTTP response headers that indicate whether the transaction is successful, the type of data being sent, the type of server, and finally the requested data.
IIS 4 supports a new version of this protocol called HTTP 1.1, which has new features that make it more efficient. These new features include the following:
- Persistent connections: An HTTP 1.1 server can keep TCP connections open after a file has been transferred, eliminating the need for a connection to be opened and closed each time a file is transferred, as is the case with HTTP 1.0.
- Pipelining: This is a process whereby an HTTP 1.1 client can send multiple Internet Protocol (IP) packets to the server without waiting for the server to respond to each packet.
- Buffering: This process allows several HTTP requests by the client to be buffered into a single packet and sent to the server, which results in faster transfer times because fewer and larger packets are used.
- Host headers: This feature enables an HTTP 1.1–compliant Web server to host multiple Web sites using a single IP address.
- Http put and http delete commands: These commands enable Web browsers to upload and delete files from Web servers using HTTP.
In May 2015 a new standard of HTTP was published as RFC 7540 – HTTP/2. The standardization effort was supported by Chrome, Opera, Firefox, Internet Explorer 11, Safari, Amazon Silk, and Edge browsers. Most major browsers had added HTTP/2 support by the end of 2015.
HTTP Headers
HTTP headers let the client and the server pass additional information with an HTTP request or response. An HTTP header consists of its case-insensitive name followed by a colon (:), then by its value. Whitespace before the value is ignored.
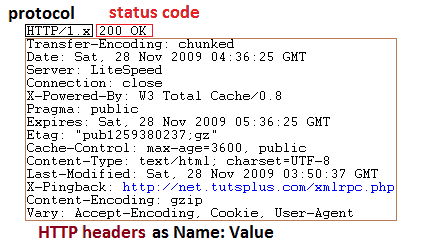
Headers can be grouped according to their contexts:
- General headers apply to both requests and responses, but with no relation to the data transmitted in the body.
- Request headers contain more information about the resource to be fetched, or about the client requesting the resource.
- Response headers hold additional information about the response, like its location or about the server providing it.
- Entity headers contain information about the body of the resource, like its content length or MIME type.
Headers can also be grouped according to how proxies handle them:
- End-to-end headers: These headers must be transmitted to the final recipient of the message: the server for a request, or the client for a response. Intermediate proxies must retransmit these headers unmodified and caches must store them.
- Hop-by-hop headers: These headers are meaningful only for a single transport-level connection, and must not be retransmitted by proxies or cached. Note that only hop-by-hop headers may be set using the
Connectiongeneral header.
HTTP Request Methods
Hypertext Transfer Protocol defines a set of request methods to indicate the desired action to be performed for a given resource. Although they can also be nouns, these request methods are sometimes referred as HTTP verbs.
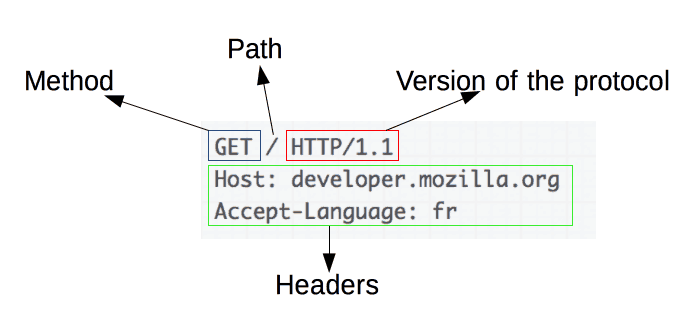
Each of them implements a different semantic, but some common features are shared by a group of them: e.g. a request method can be safe, idempotent, or cacheable.
- GET: The GET method requests a representation of the specified resource. Requests using GET should only retrieve data.
- HEAD: The HEAD method asks for a response identical to that of a GET request, but without the response body.
- POST: The POST method is used to submit an entity to the specified resource, often causing a change in state or side effects on the server.
- PUT: The PUT method replaces all current representations of the target resource with the request payload.
- DELETE: The DELETE method deletes the specified resource.
- CONNECT: The CONNECT method establishes a tunnel to the server identified by the target resource.
- TRACE: The TRACE method performs a message loop-back test along the path to the target resource.
- PATCH: The PATCH method is used to apply partial modifications to a resource.
To check the specifications documents: RFC 7231, section 4: Request methods and RFC 5789, section 2: Patch method.
Common HTTP Status Codes
| Status Code | Meaning |
| 200 | OK; request has succeeded for the method used (GET, POST, HEAD). |
| 201 | The request has resulted in the creation of a new resource reference by the returned URI. |
| 206 | The server has sent a response to byte range requests. |
| 301 | Moved Permanently is used for permanent URL redirection, meaning current links or records using the URL that the response is received for should be updated |
| 302 | Found. Redirection to a new URL. The original URL has moved. This is not an error; most browsers will get the new page. |
| 304 | Use a local copy. If a browser already has a page in its cache, and the page is requested again, some browsers (such as Netscape Navigator) relay to the web server the “last-modified” timestamp on the browser’s cached copy. If the copy on the server is not newer than the browser’s copy, the server returns a 304 code instead of returning the page, reducing unnecessary network traffic. This is not an error. |
| 400 | Sent if the request is not a valid HTTP/1.0 or HTTP/1.1 request. For example HTTP/1.1 requires a host to be specified either in the Host header or as part of the URI on the request line. |
| 401 | Unauthorized. The user requested a document but didn’t provide a valid user name or password. |
| 403 | Forbidden. Access to this URL is forbidden. |
| 404 | Not found. The document requested isn’t on the server. This code can also be sent if the server has been told to protect the document by telling unauthorized people that it doesn’t exist. |
| 408 | If the client starts a request but does not complete it within the keep-alive timeout configured in the server, then this response will be sent and the connection closed. The request can be repeated with another open connection. |
| 411 | The client submitted a POST request with chunked encoding, which is of variable length. However, the resource or application on the server requires a fixed length – a Content-Length header to be present. This code tells the client to resubmit its request with content-length. |
| 413 | Some applications (e.g., certain NSAPI plugins) cannot handle very large amounts of data, so they will return this code. |
| 414 | The URI is longer than the maximum the webserver is willing to serve. |
| 416 | Data was requested outside the range of a file. |
| 500 | Server error. A server-related error occurred. The server administrator should check the server’s error log to see what happened. |
| 503 | Sent if the quality of service mechanism was enabled and bandwidth or connection limits were attained. The server will then serve requests with that code. See the “quality of service” section. |
Hypertext Transfer Protocol Caching
The performance of websites and applications can be significantly improved by reusing previously fetched resources. Web caches reduce latency and network traffic and thus lessen the time needed to display a representation of a resource. By making use of Hypertext Transfer Protocol caching, Websites become more responsive.
What is HTTP Caching?
Caching is a technique that stores a copy of a given resource and serves it back when requested. When a web cache has a requested resource in its store, it intercepts the request and returns its copy instead of re-downloading from the originating server. This achieves several goals: it eases the load of the server that doesn’t need to serve all clients itself, and it improves performance by being closer to the client, i.e., it takes less time to transmit the resource back.
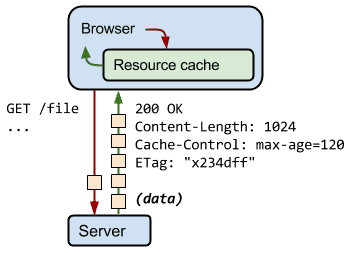
Browser cache
A browser cache holds all documents downloaded via HTTP by the user. This cache is used to make visited documents available for back/forward navigation, saving, viewing-as-source, etc. without requiring an additional trip to the server. It likewise improves offline browsing of cached content.
Proxy cache
An ISP or your company might have set up a web proxy as part of its local network infrastructure to serve many users so that popular resources are reused a number of times, reducing network traffic and latency.
See also: Internet Cache Protocol (ICP)
HTTP Messages
HTTP messages are how data is exchanged between a server and a client. There are two types of messages: requests sent by the client to trigger an action on the server, and responses, the answer from the server.
HTTP messages are composed of textual information encoded in ASCII and span over multiple lines. In HTTP/1.1, and earlier versions of the protocol, these messages were openly sent across the connection. In HTTP/2, the once human-readable message is now divided up into HTTP frames, providing optimization and performance improvements.
Web developers, or webmasters, rarely craft these textual HTTP messages themselves: software, a Web browser, proxy, or Web server, perform this action. They provide HTTP messages through config files (for proxies or servers), APIs (for browsers), or other interfaces.

History and Evolution of Hypertext Transfer Protocol
The term hypertext was coined by Ted Nelson in 1965 in the Xanadu Project, which was in turn inspired by Vannevar Bush’s 1930s vision of the microfilm-based information retrieval and management “memex” system described in his 1945 essay “As We May Think“. Tim Berners-Lee and his team at CERN are credited with inventing the original HTTP, along with HTML and the associated technology for a web server and a text-based web browser. Berners-Lee first proposed the “WorldWideWeb” project in 1989 -now known as the World Wide Web.

The first version of the protocol had only one method, namely GET, which would request a page from a server. The response from the server was always an HTML page.
The first documented version of HTTP was HTTP V0.9 (1991). Dave Raggett led the HTTP Working Group (HTTP WG) in 1995 and wanted to expand the protocol with extended operations, extended negotiation, richer meta-information, tied with a security protocol which became more efficient by adding additional methods and header fields.
Request For Comments 1945 officially introduced and recognized HTTP V1.0 in 1996. (check the original RFC 1945 document)
By March that year, pre-standard HTTP/1.1 was supported in Arena, Netscape 2.0, Netscape Navigator Gold 2.01,[12] Mosaic 2.7, Lynx 2.5, and in Internet Explorer 2.0.
The HTTP/1.1 standard as defined in RFC 2068 was officially released in January 1997. Improvements and updates to the HTTP/1.1 standard were released under RFC 2616 in June 1999.
In 2007, the HTTP Working Group was formed, in part, to revise and clarify the HTTP/1.1 specification.
HTTP/2 was published as RFC 7540 in May 2015.
HTTP and HTML confusion
Don’t confuse HTTP with HTML! HTTP is the protocol through which Web servers communicate with Web browsers. It is a control language for passing commands between clients and servers. HTML is Hypertext Markup Language, the language for constructing Web pages (the actual content passed from Web servers to Web clients in an HTTP request).
How to view HTTP headers
To view the request or response HTTP headers in Google Chrome, take the following steps :
- In Chrome, visit a URL,
right click, selectInspectto open the developer tools. - Select
Networktab. - Reload the page, select any HTTP request on the left panel, and the HTTP headers will be displayed on the right panel.
In Internet Explorer, press [F12] to launch Internet Explorer’s built-in developer tools.
- Open the Network tool using [Ctrl]+4.
- You must manually start data collection using [F5].
- Once you have some output simply double-click on the name of any object to view the HTTP headers (as well as Request Method, Response Status Code and HTTP version in relevant panels) related to it.