In today’s interconnected world, data reigns supreme. From massive e-commerce platforms to small-scale inventory management systems, the efficient organization and retrieval of data are vital for businesses of all sizes. Enter the unsung hero of the digital realm: the relational database.
This technological marvel lies at the heart of countless applications and systems, seamlessly managing and optimizing vast amounts of information. In this article, we embark on a journey into the depths of the relational database, exploring its intricacies, benefits, and real-world applications. So, fasten your seatbelts and get ready to delve into the world of data architecture like never before!
In this article:
- What is a Relational Database?
- Popular relational database frameworks
- Examples
- Non-Relational Databases Examples
- Optimization Techniques for Relational Databases
- Ensuring Data Integrity in Relational Databases
- Emerging Trends and Future Prospects of Databases
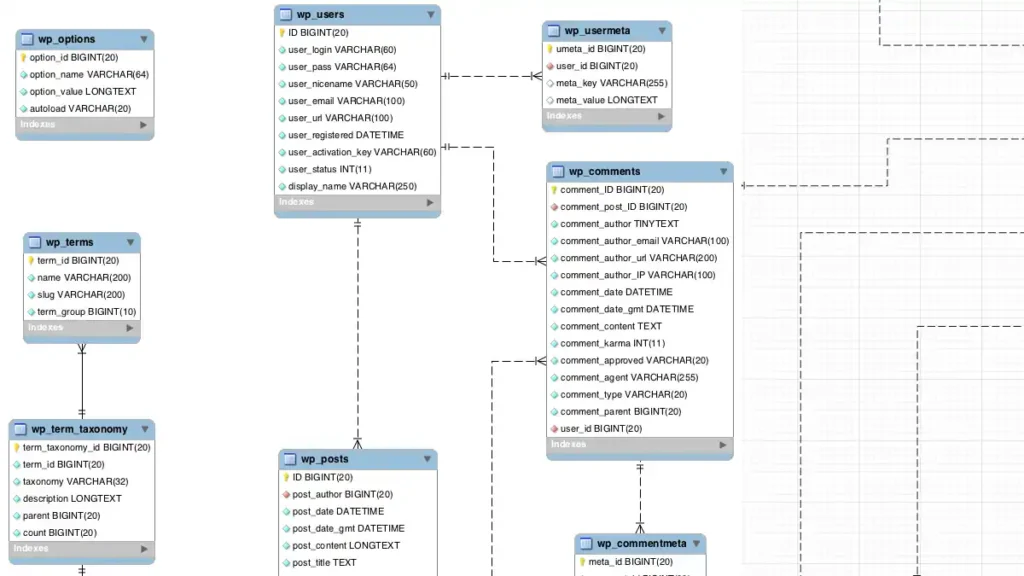
What is a Relational Database?
A relational database is a structured repository of data organized into tables, each consisting of rows and columns. Developed by Edgar F. Codd in the 1970s, this model revolutionized the way information is stored and retrieved. Its core idea lies in the concept of relationships between tables, allowing for efficient querying and manipulation of data. By employing a standardized language called Structured Query Language (SQL), users can interact with the database, performing complex operations and fetching relevant information in a matter of milliseconds.
Tables
The foundation of a relational database is the table, also known as a relation. Each table represents a specific entity or concept, such as customers, products, or orders. The columns, also called attributes, define the different properties or characteristics of the entity, while the rows contain the actual data instances. This tabular structure allows for easy scalability, flexibility, and logical organization of data.
Relationships
One of the key advantages of a relational database is its ability to establish relationships between tables through the use of primary and foreign keys. A primary key is a unique identifier within a table, ensuring each row’s distinctness, while a foreign key establishes a connection between two tables based on shared attributes. These relationships enable the database to efficiently retrieve data by combining information from multiple tables, resulting in comprehensive and meaningful results.
The most popular relational database frameworks
Several popular relational database frameworks have emerged over the years, each offering unique features and capabilities. Here are some of the most common and widely used frameworks in the realm of relational databases:
MySQL
MySQL is an open-source relational database management system (RDBMS) that has gained immense popularity for its ease of use, scalability, and strong community support. It is known for its reliability, high performance, and compatibility with various operating systems. MySQL is widely used in web applications, content management systems like WordPress, and data-driven projects.
PostgreSQL
PostgreSQL, often referred to as “Postgres,” is an advanced open-source RDBMS known for its robustness, extensibility, and adherence to SQL standards.

It offers a wide range of features, including support for advanced data types, complex queries, and geospatial data. PostgreSQL is favored by developers and organizations requiring powerful database capabilities, such as large-scale applications, data warehousing, and geographic information systems.
Oracle Database
Oracle Database is a proprietary RDBMS developed by Oracle Corporation. It is known for its enterprise-grade features, high performance, and scalability. Oracle Database offers advanced security measures, built-in analytical functions, and comprehensive management tools. It is commonly used in large-scale enterprise applications and mission-critical systems.
Microsoft SQL Server
Microsoft SQL Server is a relational database management system developed by Microsoft. It provides a robust platform for managing and analyzing data, offering features like high availability, scalability, and business intelligence capabilities. SQL Server is widely used in the Windows ecosystem and is often the preferred choice for organizations utilizing Microsoft technologies.
SQLite
SQLite is a lightweight, serverless, and self-contained RDBMS. Unlike traditional database systems, SQLite does not require a separate server process and operates directly on the application’s data files. It is widely used in embedded systems, mobile applications, and small-scale projects that require an efficient and compact database solution.
IBM Db2
Db2, developed by IBM, is a comprehensive RDBMS that offers a range of features, including high availability, security, and advanced analytics. Db2 is known for its scalability and is often used in enterprise environments requiring robust data management capabilities, such as transaction processing systems, data warehousing, and business intelligence applications.

These relational database frameworks provide developers and organizations with a solid foundation for managing and manipulating structured data. Each framework has its own strengths, features, and target use cases. The choice of framework depends on factors such as project requirements, scalability needs, performance considerations, and compatibility with existing technology stacks.
Examples of Relational Databases in Action
Relational databases are ubiquitous, playing a vital role in numerous industries and applications. Let’s explore some real-world examples that showcase the power and versatility of this data management paradigm.
Customer Relationship Management (CRM) Systems
CRM systems, widely used in sales and marketing, rely heavily on relational databases. These databases store customer information, such as contact details, purchase history, and interactions. By leveraging the relationships between tables, CRM systems can generate insights, track customer behavior, and personalize marketing campaigns.
Human Resources Management Systems (HRMS)
HRMS solutions streamline and automate HR processes, ranging from employee onboarding to payroll management. Relational databases in HRMS store employee data, including personal information, employment history, performance evaluations, and training records. The relational structure allows HR departments to efficiently search, analyze, and report on various aspects of employee information.
E-commerce Platforms
Online shopping platforms process vast amounts of product data, customer details, and transaction records. Relational databases enable seamless management of these complex datasets. For instance, product catalogs, inventory levels, customer orders, and payment information are organized across different tables and interconnected through relationships, allowing for efficient searching, inventory management, and order tracking.
Financial Systems
Relational databases are the backbone of financial systems, such as banking, accounting, and investment platforms. These databases handle large volumes of financial transactions, customer accounts, and portfolio data. By structuring data relationally, financial institutions can ensure data accuracy, support complex queries, and maintain the integrity of financial records.
Hospital Information Systems
In the healthcare sector, relational databases support comprehensive patient information management. Electronic health records (EHR) store patient demographics, medical history, diagnoses, treatments, and test results. The relational structure facilitates data retrieval for medical professionals, ensuring accurate diagnosis, treatment planning, and efficient healthcare delivery.
These examples represent just a fraction of the applications that rely on the power of relational databases. From enterprise resource planning (ERP) systems to supply chain management, the versatility and efficiency of this data management approach are unrivaled.
Non-Relational Databases Examples
While relational databases are widely used and popular, there are several other types of databases that cater to specific needs and scenarios. Let’s explore a few prominent alternatives:
NoSQL Databases
NoSQL (which stands for “not only SQL”) databases are designed to handle large-scale, unstructured, and semi-structured data. Unlike relational databases, NoSQL databases do not rely on a fixed schema and provide flexible data models. They excel in distributed and highly scalable environments, making them suitable for applications such as social media platforms, real-time analytics, and content management systems.
Document Databases
Document databases store and retrieve data in flexible, self-describing documents, typically in formats like JSON or XML. These databases are well-suited for handling unstructured and evolving data, making them popular choices for content management systems, e-commerce platforms, and applications requiring flexible schemas.
Key-Value Stores
Key-value stores are simple databases that store data as a collection of key-value pairs. They provide high-speed data access, making them ideal for caching, session management, and real-time applications. Key-value stores are often used in distributed systems to handle large volumes of frequently accessed data with low latency.
Columnar Databases
Columnar databases store data in columns rather than rows, optimizing data retrieval and analysis for specific queries. These databases excel in handling vast amounts of structured data and are commonly used in data warehousing, analytics, and business intelligence applications.
Graph Databases
Graph databases are designed to represent and store data in the form of nodes, edges, and properties. They excel at managing highly interconnected data, making them ideal for applications involving social networks, recommendation engines, fraud detection, and network analysis.
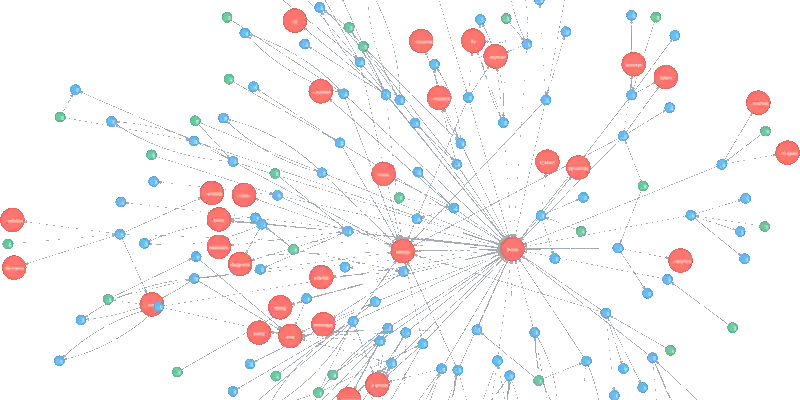
Time-Series Databases
Time-series databases specialize in handling and analyzing data points collected over time. They are designed to efficiently store, retrieve, and analyze time-stamped data, making them ideal for applications in IoT, financial markets, monitoring systems, and sensor data analysis.
These are just a few examples of the diverse range of databases available today. Each type offers specific advantages and is tailored to different use cases and data management requirements. Choosing the right database type depends on factors such as data structure, scalability needs, performance requirements, and the nature of the application at hand.
Optimization Techniques for Relational Databases
Relational databases serve as the backbone of countless applications, efficiently managing vast amounts of data. However, as the size and complexity of databases grow, it becomes crucial to employ optimization techniques to enhance performance, scalability, and overall efficiency. In this chapter, we delve into the world of optimization and explore key strategies for maximizing the potential of relational databases.
Indexing
Indexing is a fundamental optimization technique that involves creating data structures, known as indexes, to expedite data retrieval. By indexing frequently queried columns, such as primary keys or frequently filtered attributes, the database engine can quickly locate and fetch relevant data. Properly designed indexes can significantly improve query performance, reducing response times and enhancing overall system efficiency.
Query Optimization
Query optimization focuses on optimizing the execution of database queries to minimize response times. Relational database management systems employ sophisticated query optimizers that analyze query execution plans, evaluate various access paths, and choose the most efficient strategies. Techniques like query rewriting, join reordering, and cost-based optimization help improve query performance and resource utilization.
Data Normalization and Denormalization
Data normalization is the process of organizing data into logical and efficient structures, eliminating data redundancy. By reducing data duplication, updates and modifications become more efficient, ensuring data integrity and consistency. On the other hand, denormalization involves selectively reintroducing redundancy in specific cases to optimize query performance.

Denormalization can speed up complex joins and aggregations by reducing the number of table lookups, but it requires careful consideration to maintain data integrity.
Partitioning
Partitioning involves dividing large tables or indexes into smaller, more manageable pieces based on predefined criteria. Partitioning improves performance by allowing queries to operate on smaller subsets of data, reducing the overall data volume accessed. Partitioning strategies can be based on ranges, lists, or hash functions, and they facilitate data pruning, faster data loading, and improved query performance in large-scale databases.
Caching
Caching involves storing frequently accessed data in a fast-access memory layer to reduce the need for disk I/O operations. By caching query results, database systems can quickly serve subsequent requests for the same data, reducing latency and improving overall system performance. Caching mechanisms can be implemented at various levels, such as database-level caching, application-level caching, or utilizing external caching systems.
Query and Database Tuning
Regular monitoring and performance tuning are essential for maintaining optimal database performance. This involves analyzing query execution plans, identifying and optimizing slow-performing queries, fine-tuning database configuration parameters, and applying database-specific optimization techniques. Database administrators and developers play a critical role in identifying bottlenecks, optimizing queries, and ensuring efficient database operation.
By applying these optimization techniques, organizations can harness the full potential of relational databases, ensuring scalability, responsiveness, and seamless user experiences. The key lies in understanding the unique characteristics of the application, monitoring performance metrics, and continuously fine-tuning the database environment to adapt to evolving needs.
Ensuring Data Integrity in Relational Databases
Data integrity is paramount in relational databases to ensure the accuracy, consistency, and reliability of information. In this chapter, we explore the essential strategies and best practices for maintaining data integrity within the context of relational databases.
Primary Key Constraints
A primary key constraint enforces uniqueness and ensures that each record in a table has a unique identifier. By designating one or more columns as the primary key, the database system guarantees the uniqueness of values and prevents duplicate records. Primary keys establish the foundation for data integrity, enabling proper identification and referencing of records across different tables.
Foreign Key Constraints
Foreign key constraints establish relationships between tables by linking a column in one table to the primary key of another table. These constraints enforce referential integrity, ensuring that data in the referencing table corresponds to existing data in the referenced table. Foreign key constraints prevent orphaned records, maintain data consistency across related tables, and facilitate cascading updates and deletes.
Unique Constraints
Unique constraints ensure that a specific column or combination of columns contains only unique values. This constraint prevents duplicate entries in a table, guaranteeing data integrity by enforcing uniqueness at the attribute level. Unique constraints can be applied to fields like usernames, email addresses, or any other attribute that requires distinct values.
Check Constraints
Check constraints define specific rules that data values must adhere to. These rules are defined as conditions or expressions, restricting the range of acceptable values for a column. Check constraints enable data validation and integrity checks, ensuring that data meets predefined criteria. For example, a check constraint can enforce that a numeric field represents positive values only.
Data Validation and Input Sanitization
Ensuring data integrity starts at the input stage. It is crucial to validate and sanitize user input to prevent invalid or malicious data from entering the database. Input validation techniques include data type checks, range validations, format validations, and handling potential security threats like SQL injection attacks. By validating and sanitizing data before it enters the database, the risk of corrupt or inaccurate data is mitigated.
Regular Backups and Recovery
Maintaining data integrity involves safeguarding against data loss and ensuring recoverability. Regular backups are essential to creating copies of the database at specific points in time. This enables recovery in the event of accidental data deletion, system failures, or disasters. Robust backup and recovery strategies, including offsite backups and automated recovery procedures, are critical for maintaining data integrity and business continuity.
Database Auditing and Monitoring
Implementing database auditing and monitoring mechanisms helps track and detect unauthorized or suspicious activities. By monitoring database operations, access logs, and user activities, organizations can identify potential threats to data integrity, such as unauthorized modifications or access attempts. Auditing and monitoring also play a crucial role in compliance with security and regulatory requirements.
By employing these data integrity practices, organizations can maintain accurate, consistent, and trustworthy data within their relational databases. Adhering to these best practices reduces the risk of data corruption, ensures compliance with business rules, and instills confidence in the data being stored and processed.
Emerging Trends and Future Prospects of Databases
As technology advances and data-driven applications continue to evolve, the world of databases is constantly evolving. In this final chapter, we explore the emerging trends and future prospects that shape the landscape of modern databases.
Big Data and Distributed Systems
The exponential growth of data, known as big data, presents both opportunities and challenges. Databases are adapting to handle the volume, variety, and velocity of big data by leveraging distributed systems. Distributed databases distribute data across multiple nodes, enabling horizontal scalability and fault tolerance.

Technologies like Apache Hadoop, Apache Cassandra, and Apache Spark are becoming popular for managing big data workloads.
Cloud Databases
Cloud computing has transformed the way organizations store, manage, and access their data. Cloud databases provide scalable, on-demand storage and computing resources, allowing businesses to focus on their core competencies. Cloud database services, such as Amazon Aurora, Google Cloud Spanner, and Microsoft Azure Cosmos DB, offer managed solutions with high availability, global scalability, and automated backups.
Database-as-a-Service (DBaaS)
Database-as-a-Service has gained traction as a cost-effective and convenient option for managing databases. DBaaS providers, such as Amazon RDS, Azure SQL Database, and Google Cloud SQL, handle the administrative tasks of provisioning, scaling, and backup while allowing developers to focus on application development. DBaaS offerings simplify database management and provide flexibility in choosing database engines.
Graph Databases for Connected Data
Graph databases are gaining prominence for managing highly connected and complex data. With their ability to represent relationships between entities, graph databases excel in use cases such as social networks, recommendation engines, fraud detection, and knowledge graphs. As more applications require understanding relationships and analyzing connected data, the adoption of graph databases is expected to rise.
Machine Learning and Artificial Intelligence Integration
The integration of databases with machine learning (ML) and artificial intelligence (AI) capabilities is transforming data analytics and decision-making. Databases are incorporating ML and AI techniques for query optimization, anomaly detection, predictive analysis, and natural language processing. By leveraging ML and AI, databases can provide intelligent insights, automate tasks, and enhance data processing capabilities.
Blockchain and Distributed Ledger Technology
Blockchain and distributed ledger technology are revolutionizing data storage and trust mechanisms. These technologies provide decentralized and tamper-proof data storage, making them suitable for applications requiring data immutability and transparency. Blockchain-based databases find applications in supply chain management, financial transactions, and identity verification.
Real-time Data Streaming and Event-Driven Architectures
With the increasing demand for real-time data processing, databases are evolving to support streaming data and event-driven architectures. Streaming databases like Apache Kafka and Apache Pulsar allow the processing of continuous data streams, enabling real-time analytics, IoT applications, and real-time decision-making.
These emerging trends and advancements pave the way for a future where databases become more intelligent, scalable, and adaptable to diverse data requirements. As technologies like AI, cloud computing, and distributed systems continue to evolve, databases will play a central role in harnessing the power of data for innovation and growth.
By staying informed and embracing these trends, organizations can leverage the full potential of databases to drive their businesses forward and unlock new possibilities in the ever-evolving digital landscape.
With this final chapter, we conclude our exploration of the dynamic world of databases. May your data-driven endeavors be successful and transformative.