A Routing Algorithm is a mathematical procedure that a dynamic router uses to calculate entries for its routing table. It serves as the guiding mechanism that navigates data packets from their starting point to their intended endpoint..
In this comprehensive guide, we will delve into what exactly a routing algorithm is and explore its various types. We’ll break down the difference between static and dynamic routing, dissect the inner workings of routing algorithms, and categorize them into adaptive and non-adaptive classes. To enrich your understanding, we’ll also list the existing routing algorithms and clarify how they fit into these classifications. Finally, we’ll demystify the difference between routing and flooding, helping you grasp the nuances that distinguish these mechanisms.
In this article:
- What is a Routing Algorithm?
- How Do Routing Algorithms Work?
- Classification of Routing Algorithms
- Popular Routing Algorithms and Their Classification
- Conclusion
- References
1. What is a Routing Algorithm?
A routing algorithm is essentially a set of rules or protocols designed to determine the most efficient path for data packets to travel across a network. Think of it as a GPS for your data, calculating the best routes from the source to the destination, bypassing congestion and roadblocks. The concept might seem simple, but the types of routing—Static and Dynamic—add layers of complexity.
Static Routing vs. Dynamic Routing
Static Routing:
In static routing, the network administrator manually configures the routes in the routing table. It’s like setting your GPS to a single, predetermined path and never updating it. While this method is simple and consumes fewer resources, its downside is its inflexibility. For example, if a primary link fails in a network using static routing, the data cannot be rerouted unless the administrator intervenes.
Example: Imagine a three-node network A, B, and C. In static routing, if A wants to communicate with C, the admin sets a fixed path, say, A -> B -> C.
Dynamic Routing:
Dynamic routing, on the other hand, is where routing algorithms come into play. These algorithms automatically update the routing table in real-time based on network conditions. Unlike its static counterpart, dynamic routing can adapt to changes, making it more flexible and reliable.
Example: In the same three-node network A, B, and C, dynamic routing would allow for alternative paths. If A -> B -> C is congested or fails, the routing algorithm could opt for a different route like A -> D -> C if it exists.
Why Dynamic Routing Depends on Routing Algorithms
Routing algorithms are redundant in a static routing setup since there are no alternative paths to consider. In dynamic routing, however, routing algorithms are indispensable. They consider multiple factors such as bandwidth, network congestion, and even the reliability of a link to decide the most efficient path for data transmission. By continuously evaluating these parameters, routing algorithms ensure that the network adapts to any changes, providing optimal performance and reliability.
In essence, routing algorithms act as the brain of dynamic routing systems, constantly recalibrating to ensure data packets follow the most efficient path. Without them, dynamic routing would be like a headless chicken—alive but aimless.
2. How Do Routing Algorithms Work?
Routing algorithms are like the traffic cops of a network, guiding data packets on their journey from one point to another. Let’s delve into how these algorithms do their job, running as software within the router’s internal CPU.
A routing Algorithm is implemented as a routing protocol because it involves procedures and protocols that allow routers to exchange information with one another in order to calculate the metrics of various paths or routes through an internetwork. Routing algorithms base their work on the values contained in a combination of variables. These values can be determined dynamically by inspecting header information in packets directed toward the router, or they can be manually specified by network administrators. The routing algorithm then processes the values of these variables to generate the internal routing table for the router.
Routing Metrics
The variables are generally known as routing metrics and can include the following:
- Hops: The number of intermediate routers between a given network and the local router
- Latency: The time delay in processing a packet through the router or over a given route
- Congestion: The length of the packet queue at the incoming port of the router
- Load: The processor use at the router or the number of packets per second that it is currently processing
- Bandwidth: The available capacity of a route to support network traffic; decreases as network traffic increases
- Reliability: The relative amount of downtime that a particular router might experience because of malfunctions
- Maximum Transmission Unit (MTU): The largest packet size that the router can forward without needing to fragment the packet
Routing algorithms are usually implemented as a combination of dynamic (real-time calculated) and static (specified by the network administrator) factors. Algorithms are usually implemented in a distributed fashion, with each router independently calculating its own routing tables, and in the case of dynamic routers, exchanging routing information with each other as well. This provides a degree of fault tolerance for the routing network: If one router goes down, all other routers can reconfigure their routing tables to route traffic around the failed router. When the failed router is restored, the routing tables are recalculated. Some routing algorithms support forwarding packets over several paths to a given destination (when such multiple paths exist). They can thus better manage network traffic by load balancing packets accordingly.
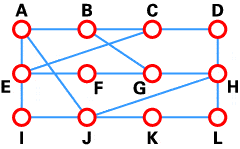
One major distinction between routing algorithms involves the space within which they operate.
Flat Routing Space
In a flat routing space, all routers are peers, while in a hierarchical routing space, different routing domains, areas, or autonomous systems are connected using a backbone routing network.
Hierarchical Routing space
The advantage of a hierarchical routing space is that it reduces the amount of intercommunication traffic that must take place between routers in order for them to calculate their routing tables. For example, routers that forward traffic only within their own routing table do not need to exchange routing information with routers in other domains. The downside, of course, is that a hierarchical system is much more difficult to implement and maintain than a flat routing space.
From a mathematical point of view, routing algorithms come in two common types: link state routing algorithms and distance vector routing algorithms. A link state routing algorithm is a hierarchical routing space algorithm that forms the basis of the Open Shortest Path First (OSPF) Protocol, while a distance vector routing algorithm is a flat routing space algorithm that forms the basis of the Routing Information Protocol (RIP). From a network administrator’s perspective, the differences between these algorithms are as follows:
- A routing protocol based on the distance vector routing algorithm is simpler to implement than one based on the link state routing algorithm. Link state algorithms require more processing power, and routers that implement it are generally more costly.
- Routing loops are less likely to occur when the link state algorithm is used.
- The two algorithms offer a trade-off with respect to network traffic between routers. Specifically, routers using the distance vector algorithm periodically send their entire routing table to other routers, but only to routers one hop away, while the link state algorithm floods the entire internetwork with information from each router, but only updated information is sent when needed.
3. Classification of Routing Algorithms
Routing algorithms are not a one-size-fits-all solution; they come in various types and classes to suit different networking needs. In this chapter, we will delve into two major categories: Adaptive and Non-Adaptive algorithms, breaking down each into its subtypes to give you a comprehensive understanding of the landscape.
Adaptive Routing Algorithms
Adaptive routing algorithms, also known as dynamic algorithms, change their routing decisions to adapt to the network conditions. They are primarily divided into three types:
- Centralized Algorithm: In this setup, a single central node (usually a powerful router or server) calculates routes for all the routers in the network. The central node gathers all the network information, runs the routing algorithm, and then sends the updated routing tables to the other routers.
- Example: A network management system that continually monitors network conditions and centrally updates all routing tables.
- Isolation Algorithm: Routers using isolation algorithms operate independently without much cooperation with their neighbors. They make their routing decisions based on locally available information, such as queue lengths at adjacent routers or current traffic conditions.
- Example: Algorithms designed for mobile ad-hoc networks (MANETs), where rapid topology changes make centralized control impractical.
- Distributed Algorithm: This is a more democratic approach, where every router communicates with its neighbors to update its routing table. There is no single point of failure, making it robust and fault-tolerant.
- Example: Distance Vector Routing and Link State Routing fall under this category, and they are commonly used in various types of networks.
Non-Adaptive Routing Algorithms
Unlike their adaptive counterparts, non-adaptive routing algorithms don’t change their routing decisions based on network conditions. They are generally simpler and quicker but are not as flexible in adapting to network changes. The most common types are:
- Flooding: Every incoming packet is sent through every outgoing link except the one it arrived on. This is a simple yet resource-intensive method and is generally used in controlled environments or for specific use-cases like network discovery.
- Example: The ARP protocol employs flooding to discover the MAC address of a host in a local network segment.
- Random Walks: In this method, packets are moved randomly from one node to another until they reach their destination. While not efficient, this method is easy to implement and is sometimes used in scenarios where network topology is not well-defined.
- Example: Random walks are often seen in mesh networks where there’s no clear path, and the packet eventually finds its way to the destination through random hops.
Clarifying Routing Algorithms Classification
Navigating the world of routing algorithms can be like negotiating a maze with multiple dimensions. Not only are there ‘Adaptive’ and ‘Non-Adaptive’ types, but there are also ‘Flat’ and ‘Hierarchical’ routing spaces, and even mathematical classifications like ‘Link State’ and ‘Distance Vector’ algorithms. In this section, we aim to simplify this complex landscape into understandable segments, making it easier for you to select the best algorithm for your needs.
Primary Classification: Adaptive vs. Non-Adaptive
At the most basic level, algorithms are categorized into Adaptive and Non-Adaptive types based on their ability to adapt to network conditions. We discussed this in-depth in the previous section.
Spatial Classification: Flat vs. Hierarchical
Another way to categorize routing algorithms is based on the ‘space’ within which they operate.
- Flat Routing Space: Here, all routers are considered equal, and every router communicates with each other.
- Hierarchical Routing Space: Routers are organized into different domains or levels, reducing the need for universal communication between all routers.
Mathematical Classification: Link State vs. Distance Vector
From a mathematical standpoint, algorithms can be categorized as:
- Link State Algorithms: These are more complex but offer higher precision and are generally used in hierarchical routing spaces.
- Distance Vector Algorithms: Simpler to implement but generally less precise, these are often used in flat routing spaces.
The Interplay
Understanding these classifications isn’t just an academic exercise; they often interrelate and influence each other. For example:
- A ‘Centralized Algorithm’ (from the Adaptive category) may operate best within a ‘Hierarchical Routing Space’.
- ‘Link State Algorithms’ are often ‘Adaptive’ and suited for ‘Hierarchical’ spaces due to their complexity and precision.
By knowing how these categories overlap and interact, you can make a more informed decision tailored to your specific networking requirements.
4. Popular Routing Algorithms and Their Classification
Understanding the intricate classifications of routing algorithms sets the stage for the main act—learning about popular algorithms that are widely used in today’s networks. In this chapter, we’ll take you through some key algorithms and slot them into the categories we’ve previously outlined.
Distance Vector Routing (DVR)
- Classification: Adaptive, Flat Routing Space, Distance Vector
- Key Features: Simple to implement, but can lead to routing loops.
- Use-Cases: Smaller networks, LANs.
- Learn more
Link State Routing (LSR)
- Classification: Adaptive, Hierarchical Routing Space, Link State
- Key Features: More complex but avoids routing loops and offers greater accuracy.
- Use-Cases: Enterprise networks, ISPs.
- Learn more
Open Shortest Path First (OSPF)
- Classification: Adaptive, Hierarchical Routing Space, Link State
- Key Features: Supports multiple equal-cost routes, robust, and scalable.
- Use-Cases: Large enterprise networks.
- Learn more
Routing Information Protocol (RIP)
- Classification: Adaptive, Flat Routing Space, Distance Vector
- Key Features: Easy to configure but less efficient for larger networks.
- Use-Cases: Small to medium-sized networks.
- Learn more
Border Gateway Protocol (BGP)
- Classification: Adaptive, Hierarchical Routing Space
- Key Features: Used for routing between autonomous systems, very scalable.
- Use-Cases: Internet backbone routing.
- Learn more
Dijkstra’s Algorithm
- Classification: Adaptive, Hierarchical Routing Space, Link State
- Key Features: Finds the shortest path in a weighted graph, foundational for many other algorithms.
- Use-Cases: OSPF uses a variant of Dijkstra’s algorithm.
Bellman-Ford Algorithm
- Classification: Adaptive, Flat Routing Space, Distance Vector
- Key Features: Simple and effective but slower than Dijkstra’s for finding the shortest path.
- Use-Cases: Used in RIP.
Flooding
- Classification: Non-Adaptive, Flat Routing Space
- Key Features: Sends packets to all outgoing links, resource-intensive.
- Use-Cases: Network discovery, specific controlled environments.
Random Walks
- Classification: Non-Adaptive, Flat Routing Space
- Key Features: Packets take random paths towards the destination.
- Use-Cases: Mesh networks, decentralized setups.
These algorithms are the titans of routing, each with its unique characteristics and ideal operational environments. By understanding where each fits into the broader classification scheme, you can more easily select the algorithm that best suits your specific needs. Whether you require the simplicity of Distance Vector Routing or the robustness of OSPF, the right tool for the job is now just a choice away.
5. Conclusion
Routing algorithms are more than just a technicality; they are the pillars that support the integrity, efficiency, and resilience of a network. As we’ve explored, their classification isn’t a one-size-fits-all approach but a multifaceted schema, including Adaptive vs. Non-Adaptive types, Flat vs. Hierarchical routing spaces, and mathematical categories like Link State and Distance Vector algorithms. And as technology evolves, so do these algorithms, adapting to the complexities and challenges of modern networking.
Whether you are a network engineer, a student, or simply someone intrigued by the intricacies of computer networking, understanding routing algorithms is invaluable. It empowers you to make informed choices, tailor solutions, and even innovate in this ever-evolving field.
6. References
- Huitema, C. (2000). Routing in the Internet (2nd ed.). Prentice Hall.
- Kurose, J. F., & Ross, K. W. (2016). Computer Networking: A Top-Down Approach (7th ed.). Pearson.
- Tanenbaum, A. S., & Wetherall, D. (2010). Computer Networks (5th ed.). Prentice Hall.
- “Introduction to Routing Algorithms” – Cisco Systems. [Online]. Available: Cisco Website
- “OSPF vs RIP: An Analysis” – Juniper Networks White Paper. [Online]. Available: Juniper Website
- RFC 2328 – OSPF Version 2. [Online]. Available: IETF Website
- RFC 2453 – RIP Version 2. [Online]. Available: IETF Website
- Wang, F. Y., Carley, K. M., Zeng, D., & Mao, W. (2007). “Social Computing: From Social Informatics to Social Intelligence“. IEEE Intelligent Systems, 22(2), 79-83.
- What is Routing (Network Encyclopedia)
- The Routing Protocol (Network Encyclopedia)