Distributed systems have moved from being a specialized subject to the backbone of today’s computing world. Whether it’s the Internet itself, cloud computing platforms, or large-scale data processing systems, the influence of distributed systems is pervasive. For computer science students stepping into the domain, understanding the complexities and design paradigms of distributed systems is more than just a course requirement—it’s essential for innovating the next generation of technology.
In this article:
- What is a Distributed System?
- Fundamental Components of Distributed Systems
- Design Paradigms
- Data Distribution Strategies
- Time and Synchronization in Distributed Systems
- Concurrency and Coordination
- Fault Tolerance and Recovery
- Scalability Challenges
- Security in Distributed Systems
- Real-World Applications
- The Future of Distributed Systems
- Further Readings and Resources

This article aims to offer a thorough overview of distributed systems, dissecting its multiple layers, challenges, and real-world applications. Tailored for the college student, we endeavor to simplify these inherently complex systems into manageable and understandable components. Grab your coffee and let’s begin!
What is a Distributed System?
In its most elementary form, a distributed system consists of multiple interconnected computers that work in tandem to achieve a common objective. Unlike a monolithic system where all the computational activities take place on a single machine, a distributed system divides the workload across multiple computers, or nodes, usually connected via a network.
The division of labor is such that each node can execute its tasks concurrently, often without the need for centralized control. This enables distributed systems to provide increased performance, scalability, and fault-tolerance. For example, when you use a search engine like Google, your query is distributed among thousands of computers that simultaneously perform computations to return relevant results.
Fundamental Components of Distributed Systems
In our endeavor to decode the anatomy of distributed systems, the logical starting point is to dissect its building blocks. A comprehensive understanding of these components not only lays the foundation for mastering the subject but also plays a vital role in shaping system design and architecture. Here, we delve deep into the fundamental elements that collectively constitute a distributed system: Nodes, Networks, and Communication Methods.
Nodes
In the context of a distributed system, a node typically refers to a single computing device, often a server or a workstation, that partakes in the system’s broader computational effort. But nodes are far more than just hardware; they encapsulate a computational environment comprising an operating system, local memory, computational processors, and often, local storage.
- Types of Nodes:
- Computation Nodes: Primarily focused on computational tasks.
- Data Nodes: Specialized in storing and managing data.
- Gateway Nodes: Act as an interface between different networks or sub-systems.
- Characteristics of Nodes:
- State: The local condition of a node, including data values, computational markers, and system settings.
- Role: The function a node performs within a system can vary—some nodes may take on specialized roles, like acting as a leader in leader-based consensus algorithms.
Networks
The network is the binding fabric that interconnects nodes in a distributed system. It is responsible for data transfer and synchronization between nodes.
- Topologies:
- Star: Centralized around one or more nodes.
- Mesh: Every node is connected to every other node.
- Hybrid: A combination of two or more different types of topologies.
- Communication Protocols:
- TCP/IP: The most commonly used protocol, reliable but can be slower.
- UDP: Faster but less reliable.
- Custom Protocols: Sometimes systems require specialized communication protocols tailored for specific needs.
Communication Methods
The interaction between nodes is perhaps the most critical aspect of a distributed system. The communication model a system adopts directly influences its efficiency, fault tolerance, and scalability.
- Message-Passing:
- Asynchronous vs. Synchronous: In asynchronous systems, the sender does not wait for the message to be received. In contrast, synchronous systems block the sender until acknowledgment is received.
- Shared Memory:
- Consistency Models: How the system ensures that all nodes have a coherent view of the data.
- Access Controls: Read/Write permissions and lock mechanisms to manage concurrent access.
- Stream-Oriented Communication:
- Data Streams: Continuous flow of data, usually in real-time systems.
- Control Streams: Direct the flow of computation, such as command and control signals.
- Remote Procedure Calls (RPC):
- Synchronous RPCs: The caller is blocked until the procedure completes.
- Asynchronous RPCs: The calling function proceeds without waiting for the result.
This intricate interplay between nodes, networks, and communication methods forms the foundational stratum of any distributed system. As you navigate through the complexities of distributed computing, a robust grasp of these fundamentals will act as your compass, guiding you through the challenges that lie ahead.
Design Paradigms in Distributed Systems
Understanding the architectural philosophies behind distributed systems is akin to mastering the blueprint of a complex edifice. While the foundational components like nodes and networks provide the structural elements, the design paradigm dictates the interaction patterns and roles of these components within the system. Here we explore three dominant design paradigms: Client-Server, Peer-to-Peer, and Hybrid Models.
Client-Server
In the Client-Server paradigm, nodes are designated either as clients, which request services, or servers, which provide services.
- Roles:
- Client: Initiates requests for resources or services.
- Server: Satisfies client requests by offering resources or executing services.
- Characteristics:
- Scalability: Server farms or clusters can be used to scale up.
- Single Point of Failure: If the server fails, the system can become non-operational.
- Load Balancing: Distributing incoming requests across multiple servers to ensure no single server is overwhelmed.
Peer-to-Peer (P2P)
The Peer-to-Peer paradigm operates on the egalitarian principle where each node has equivalent capabilities and responsibilities.
- Roles:
- Peer: Can act as both a client and a server.
- Characteristics:
- Decentralization: No single point of failure or control.
- Scalability: New peers contribute additional resources, making it inherently scalable.
- Self-organization: Peers can join or leave at will; the network self-organizes to accommodate these changes.
Hybrid Models
As the name suggests, Hybrid models combine elements of both Client-Server and Peer-to-Peer paradigms.
- Roles:
- Hybrid Peer: Can act as a client, a server, or both depending on the context.
- Characteristics:
- Flexibility: Can adapt to different needs and scenarios.
- Complexity: The most complex to implement and manage due to the combination of multiple paradigms.
Data Distribution Strategies
The art of managing data in a distributed system is both a boon and a bane. While distributing data can significantly speed up access and processing, it also presents unique challenges such as data consistency, latency, and fault tolerance. In this section, we dissect the primary strategies for data distribution: Data Replication, Partitioning, and Sharding.
Data Replication
In this strategy, the same data is stored on multiple nodes to improve data availability and fault tolerance.
- Types:
- Full Replication: Every node has a copy of the entire dataset.
- Partial Replication: Only a subset of data is replicated across nodes.
- Consistency Models:
- Strong Consistency: Ensures all replicas are updated before an operation is deemed complete.
- Eventual Consistency: Allows for some temporal data inconsistency but guarantees that all replicas will eventually have the same data.
Data Partitioning
Here, data is divided into smaller, manageable chunks, and each chunk is assigned to a specific node.
- Types:
- Horizontal Partitioning: Divides the dataset into rows.
- Vertical Partitioning: Divides the dataset into columns.
- Partitioning Schemes:
- Range-based: Data is partitioned based on a range of values.
- Hash-based: A hash function determines the partition for each data item.
Data Sharding
Sharding is an extension of partitioning but aimed at distributed databases. Each shard operates independently, allowing for parallel operations and scalability.
- Types:
- Geographic Sharding: Data is sharded based on geographic locations.
- Directory-based Sharding: A directory service maintains a lookup for shard locations.
- Shard Keys:
- The attribute on which the data is sharded. The choice of shard key can significantly impact performance.
By mastering these design paradigms and data distribution strategies, you equip yourself with the tools necessary to architect robust and efficient distributed systems. Each paradigm and strategy offers its unique blend of advantages and challenges, and the choice often depends on the specific requirements and constraints of your system.
Time and Synchronization in Distributed Systems
Navigating through the labyrinthine world of distributed systems, one quickly realizes the importance of a seemingly mundane concept: time. Time in distributed systems isn’t just a simple ticking clock on the wall; it’s an intricate dance of coordination that ensures the integrity and consistency of operations across nodes.
Logical Clocks
Initially, you might find the idea of logical clocks counterintuitive. Unlike physical clocks that measure real-world time, logical clocks are used to order events in a distributed system. Lamport’s Logical Clocks and Vector Clocks are two prevalent models.
- Lamport’s Clocks: These provide a “happened-before” relationship between different events.
- Vector Clocks: More advanced than Lamport’s, these clocks allow for capturing concurrent and causally related events.
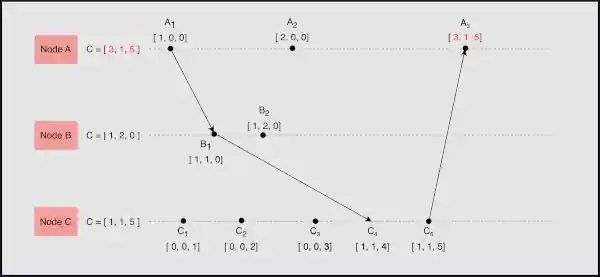
Time Synchronization
Moving along, you come across the need to synchronize physical clocks in your nodes. Techniques like Network Time Protocol (NTP) or Precision Time Protocol (PTP) are commonly utilized.
- NTP: Suitable for a wider range of applications but offers less precision.
- PTP: Offers high precision but might be overkill for less time-sensitive applications.
Concurrency and Coordination
Subsequently, we delve into the enigmatic realms of concurrency and coordination, two facets of distributed systems that stand as pillars supporting the functional integrity of operations. Managing these is tantamount to orchestrating a complex ballet where each dancer knows not just their moves, but also how these moves fit into the grander scheme.
Locks and Mutexes
Initially, let’s talk about locks and mutexes. These are the simplest tools for ensuring that resources aren’t accessed by multiple processes simultaneously.
- Locks: These are binary; a resource is either locked or not.
- Mutexes: These are more advanced, allowing for various levels of locking and more complex conditions for resource access.
Two-Phase Commit and Paxos
Venturing deeper, one discovers algorithms designed for consensus in distributed systems—Two-Phase Commit and Paxos.
- Two-Phase Commit: It’s a blocking algorithm where a coordinator node requires acknowledgments from all participant nodes to commit a transaction.
- Paxos: This algorithm allows for non-blocking consensus and is highly fault-tolerant but can be more complex to implement.
Fault Tolerance and Recovery
Finally, yet importantly, we encounter the indispensable concept of fault tolerance and recovery. In the ever-so-vast expanse of distributed systems, faults are not just a possibility; they are a guarantee.
Redundancy and Failover
Firstly, the strategies of redundancy and failover act as your first line of defense against system faults.
- Redundancy: Involves having backup nodes or resources that can take over in case of a failure.
- Failover: The process by which secondary nodes become primary nodes upon the failure of the original primary node.
Checkpointing and Rollback
Subsequently, the techniques of checkpointing and rollback serve as your safety nets, allowing your system to revert to a previously stable state in case of failures.
- Checkpointing: Periodically saving the state of a system.
- Rollback: Reverting to the most recent checkpoint to recover from a failure.
By thoroughly understanding these three domains—time and synchronization, concurrency and coordination, and fault tolerance and recovery—you are arming yourself with the critical knowledge necessary for designing resilient, efficient, and scalable distributed systems. The journey through these chapters is akin to peeling an onion, revealing layer after layer of complexity, but also offering a plethora of tools and techniques to manage that complexity effectively.
Scalability Challenges
As we pivot from the realm of fault tolerance, another glaring challenge emerges on the horizon—scalability. Scalability is the alchemy that turns a good distributed system into a great one. It is the capability of a system to grow and manage increased demand gracefully, and it is inextricably linked to three key concepts: Load Balancing, Elasticity, and Decentralization.
Load Balancing
Firstly, we must ponder upon the pivotal role of load balancing. At its core, load balancing is about distributing tasks across multiple computing resources. Strategies range from the straightforward Round Robin algorithm to more sophisticated ones like Least Connection methods.
- Round Robin: Each node receives a job in turn, providing a cyclical balance.
- Least Connection: Jobs are sent to the node with the fewest active connections.
Elasticity
Subsequently, we venture into the territory of elasticity. Elasticity is about dynamically adding or removing resources in response to changes in demand. Technologies like AWS Auto Scaling have brought elasticity to the mainstream, providing auto-adjustable resources based on real-time metrics.
- Vertical Scaling: Increasing the capacity of a single resource.
- Horizontal Scaling: Increasing the number of resources in the system.
Decentralization
Lastly, decentralization stands as the third pillar. Decentralized systems have multiple points of control, which offers advantages in terms of redundancy and potentially, fault tolerance. Peer-to-peer networks and blockchain technology epitomize this approach.
Security in Distributed Systems
Now, shifting our focus from scalability, let us delve into another equally critical dimension—security. In the vast, interconnected landscape of distributed systems, security issues such as Authentication, Authorization, and Encryption are not just add-ons; they are necessities.
Authentication
First off, authentication acts as the initial gatekeeper. Before you can interact with a system, it needs to know who you are. Mechanisms like Single Sign-On (SSO) and OAuth offer robust ways to manage this.
Authorization
Following closely is authorization. Knowing who you are is just the beginning; the system also needs to know what you are allowed to do. Role-based access control (RBAC) is a standard method to handle this complex problem.
Encryption
Finally, we reach the bedrock of secure communication—encryption. Protocols like TLS and algorithms like AES are employed to ensure that the data traveling between nodes remains confidential and intact.
Real-World Applications
Transitioning from the theoretical to the practical, let’s explore some real-world applications of distributed systems. When you stream a movie on Netflix or buy something from Amazon, you’re indirectly interacting with complex distributed systems.
- Streaming Services: Netflix employs a globally distributed architecture to provide low-latency streaming.
- E-commerce: Systems like Amazon need to manage vast, distributed databases to provide real-time information about inventory, pricing, and user data.
In summary, distributed systems are far more than a sum of their parts, thanks to the sophisticated orchestration of technologies and techniques like scalability, security, and application-specific optimizations. As you tread further into this intricate ecosystem, keep these foundational principles in mind. They will serve as your compass, guiding you through the complexity and towards mastering the art and science of distributed systems.
The Future of Distributed Systems
Steering our narrative toward the future, we arrive at a compelling juncture in our discussion—the emerging trends that are shaping the next generation of distributed systems. Significantly, these can be categorized into three main domains: Microservices, Edge Computing, and Quantum Computing.
Microservices
Initially, let’s focus on microservices, an architectural style that structures an application as a collection of loosely coupled services. This modularity offers numerous advantages, including the ability to scale components independently. Companies like Netflix and Uber are already leveraging microservices to deliver highly responsive and scalable applications.
Edge Computing
Next, we pivot to the burgeoning field of edge computing. In contrast to cloud computing, which centralizes data processing in massive data centers, edge computing pushes processing closer to the source of data generation—usually Internet of Things (IoT) devices. This trend is driven by the need for low-latency processing and data privacy.
Quantum Computing
Finally, on the cutting edge of technology lies quantum computing. Still largely experimental, quantum computing promises computational speeds unattainable with current systems. As quantum technologies mature, they could revolutionize distributed computing, offering solutions to problems that are currently intractable.
Further Readings and Resources
Having journeyed through the complexities and intricacies of distributed systems, you may be yearning for more resources to deepen your understanding. Fortuitously, the field is rich in literature, both academic and practical.
- Books:
- “Designing Data-Intensive Applications” by Martin Kleppmann: A comprehensive guide for anyone dealing with big data architectures.
- “Distributed Systems: Concepts and Design” by George Coulouris et al.: A classic textbook that covers the fundamentals.
- RFCs:
- Online Courses:
- “Introduction to Cloud Computing” by IBM on Coursera: A beginner’s course on cloud-based distributed systems.
- “Distributed Systems and Cloud Computing with Java” on Udemy: A hands-on approach to learning distributed computing.
As you navigate through these resources, remember that the world of distributed systems is ever-evolving. Staying current is not just a necessity but an ongoing commitment to mastering a fascinating and boundless field.