Fault tolerance is a crucial concept in computer science and networking that ensures systems continue to operate smoothly even when faced with hardware failures, network issues, or other unforeseen challenges. In this comprehensive guide, we will delve deep into the mechanisms of fault tolerance, exploring its components like redundancy and replication. Whether you’re a student, a professional, or simply curious about how fault tolerance maintains consistent system performance, this article will serve as your go-to resource.
In this article:
- What is Fault Tolerance?
- History and Evolution of Fault Tolerance
- Redundancy
- Replication
- Fault-Tolerant Architectures
- Fault Detection Mechanisms
- Fault Recovery Techniques
- Fault Tolerance in Cloud Computing
- Case Studies
- Conclusion
- References

1. What is Fault Tolerance?
Fault Tolerance is any mechanism or technology that allows a computer or operating system to recover from a failure. In fault tolerant systems, the data remains available when one component of the system fails.
Here are some examples of fault-tolerant systems:
- Transactional log files that protect the Microsoft Windows registry and allow recovery of hives
- RAID 5 disk systems that protect against data loss
- Uninterruptible power supply (UPS) to protect the system against primary power failure
A fault-tolerant design enables a system to continue its intended operation, possibly at a reduced level, rather than failing completely, when some part of the system fails. The term is most commonly used to describe computer systems designed to continue more or less fully operational with, perhaps, a reduction in throughput or an increase in response time in the event of some partial failure. That is, the system as a whole is not stopped due to problems either in the hardware or the software. An example in another field is a motor vehicle designed so it will continue to be drivable if one of the tires is punctured, or a structure that is able to retain its integrity in the presence of damage due to causes such as fatigue, corrosion, manufacturing flaws, or impact.
Types of Faults: Transient, Intermittent, and Permanent
Understanding the different types of faults is pivotal for implementing effective fault tolerance. Here are the primary categories:
- Transient Faults: These are temporary faults that occur randomly and are often hard to reproduce. They can be caused by a temporary overload, a short-lived bug, or external conditions like electrical interference.
- Intermittent Faults: These faults occur sporadically and may become more frequent over time, usually signaling an impending permanent fault. They are often caused by aging hardware or fluctuating environmental conditions.
- Permanent Faults: As the name suggests, these are faults that cause irreversible damage or failure to a component. Immediate intervention, such as replacing hardware or updating software, is required to resume normal operation.
Each fault type requires a different approach to fault tolerance, ranging from simple error handling and retry mechanisms for transient faults, to backup systems for permanent faults.
Scope: Software vs Hardware
Fault tolerance isn’t limited to any one aspect of technology—it spans both hardware and software realms.
- Hardware Fault Tolerance: This usually involves redundant components that can take over in case a primary component fails. For example, many servers have dual power supplies so that if one fails, the other can maintain the system.
- Software Fault Tolerance: In the software domain, fault tolerance often involves techniques like error handling, data replication, and algorithmic checks that validate the data integrity. Software solutions can also help to manage and swap hardware components in real-time in case of failure.
In practice, robust fault tolerance usually involves a blend of both hardware and software solutions. For instance, a cloud storage service might use multiple backup servers (hardware) and also implement real-time data replication (software) to ensure uninterrupted service.
2. History and Evolution of Fault Tolerance
Early Mechanisms
Initially, fault tolerance emerged as a crucial necessity for mainframe computers in the 1950s and 1960s. Back then, hardware components were both expensive and fragile. Therefore, engineers crafted rudimentary fail-safes like mirrored disk drives and dual modular redundancy. These early solutions primarily focused on hardware failures, offering minimal insulation against software errors or cyber threats.
Transitioning into the 1970s, the advent of microprocessors significantly altered the landscape. Companies like IBM introduced error-correcting code memory, thereby elevating fault tolerance to a new level. This innovation allowed systems to detect and correct single-bit errors, enhancing reliability substantially.
Evolution in Distributed Systems
With the rise of distributed systems in the late 1980s and 1990s, fault tolerance faced a paradigm shift. Now, the focus expanded from individual components to networked systems, compelling engineers to think beyond hardware redundancies. Distributed systems introduced an array of new challenges, such as network partitioning and data inconsistency.
However, these challenges also catalyzed innovation. Techniques like consensus algorithms, state-machine replication, and Byzantine fault tolerance started gaining prominence. These methods, such as the Paxos and Raft algorithms, enabled systems to maintain consistency and availability even when individual nodes failed.
Additionally, the arrival of cloud computing revolutionized fault tolerance once more. Now, we have systems that automatically balance loads, replicate data, and even shift workloads to different geographical locations in real-time to mitigate the risks of local outages.
In summary, fault tolerance has come a long way from its early days of hardware-centric solutions. The shift to distributed and cloud-based systems has not only magnified its complexities but has also amplified its importance. Thus, understanding its history helps us appreciate the sophisticated mechanisms we have today and informs our strategies for developing even more resilient systems in the future.
3. Redundancy
Redundancy is the provision of functional capabilities that would be unnecessary in a fault-free environment. This can consist of backup components that automatically “kick in” if one component fails. For example, large cargo trucks can lose a tire without any major consequences. They have many tires, and no one tire is critical (with the exception of the front tires, which are used to steer, but generally carry less load, each and in total, than the other four to 16, so are less likely to fail). The idea of incorporating redundancy in order to improve the reliability of a system was pioneered by John von Neumann in the 1950s.
Two kinds of redundancy are possible:
- Space redundancy: provides additional components, functions, or data items that are unnecessary for fault-free operation. Space redundancy is further classified into hardware, software and information redundancy, depending on the type of redundant resources added to the system.
- Time redundancy: the computation or data transmission is repeated and the result is compared to a stored copy of the previous result. The current terminology for this kind of testing is referred to as In Service Fault Tolerance Testing or ISFTT for short.
4. Replication
Spare components address the first fundamental characteristic of fault tolerance in three ways:
- Replication: Providing multiple identical instances of the same system or subsystem, directing tasks or requests to all of them in parallel, and choosing the correct result on the basis of a quorum;
- Redundancy: Providing multiple identical instances of the same system and switching to one of the remaining instances in case of a failure (failover);
- Diversity: Providing multiple different implementations of the same specification, and using them like replicated systems to cope with errors in a specific implementation.
All implementations of RAID, redundant array of independent disks, except RAID 0, are examples of a fault-tolerant storage device that uses data redundancy.
5. Fault-Tolerant Architectures
High Availability Clusters
High Availability Clusters serve as one of the foundational pillars in fault-tolerant design. These clusters contain multiple nodes that can quickly take over if one node fails, ensuring that the system remains operational. Load balancing and data replication are typically built into these clusters, offering both performance gains and fault tolerance. This approach minimizes service interruptions and provides a seamless experience for end-users.
Distributed Systems
In the realm of fault-tolerant architectures, distributed systems stand out for their robustness and scalability. Here, components spread across multiple servers or locations share the workload. Such an architecture inherently allows for fault tolerance since a single point of failure generally doesn’t lead to a system-wide outage. Methods like sharding and partitioning help manage data and tasks more effectively, fortifying the system’s fault tolerance even further.
RAID Systems
RAID (Redundant Array of Independent Disks) is a technology designed to improve data storage reliability and performance. Various RAID levels offer different balances of performance, fault tolerance, and data protection. For example, RAID 1 mirrors the same data on two or more disks, while RAID 5 uses block-level striping and distributes parity across all disks. These mechanisms make RAID systems highly resilient to disk failures, thereby adding an additional layer of fault tolerance.
6. Fault Detection Mechanisms
Heartbeats
Heartbeat mechanisms involve sending periodic signals between components in a system to check for responsiveness. If a component fails to send or acknowledge a heartbeat within a predetermined period, the system flags it as faulty. This mechanism is especially crucial in high-availability clusters, where rapid detection and recovery from failure are essential.
Timeouts
Timeouts are another vital mechanism in fault detection. Here, a predetermined period is set for certain operations or responses. If the operation doesn’t complete or the response isn’t received within this time, the system considers the operation as failed or the component as unresponsive. Timeouts are ubiquitous, especially in distributed systems where network latency and partial failures are common.
Quorum
In a distributed system, a quorum refers to the minimum number of nodes that must be operational to proceed with an operation. The concept ensures that actions like data writing and configuration changes occur only when a sufficient number of nodes agree, thus maintaining system consistency and integrity. In case a quorum is not achieved, the operation is either retried or aborted, averting potential faults.
By delving into these diverse architectures and detection mechanisms, we uncover the intricate web of technologies that fortify modern systems against failures. These concepts provide a rich toolkit for building robust, fault-tolerant systems that can meet the demanding needs of today’s applications and services.
7. Fault Recovery Techniques
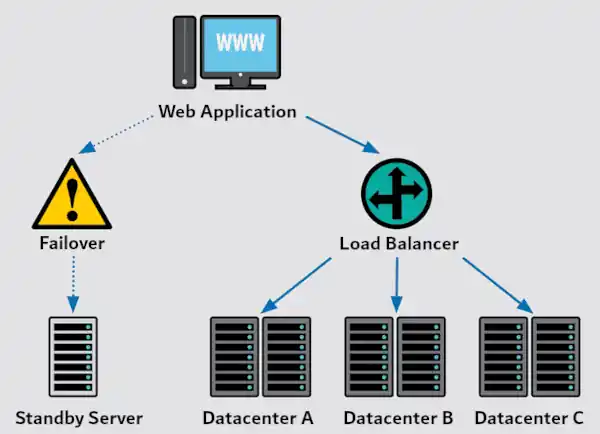
Failover
Transitioning smoothly, let’s delve into failover—a cornerstone in fault recovery. In essence, failover is an automatic switch to a redundant system or component upon failure. As soon as the system detects a fault, it transfers control to a backup, minimizing downtime. In databases and high-availability clusters, for instance, failover mechanisms are indispensable.
Checkpointing
Next on our list is checkpointing. This technique periodically saves the state of a system, essentially creating a “checkpoint.” If a failure occurs, the system reverts back to the last stable checkpoint. Notably, checkpointing is common in long-running computations and distributed applications. It provides a solid fallback position, preserving data integrity during glitches.
Rejuvenation
Finally, let’s talk about rejuvenation. This technique aims to pre-emptively restart components, thereby avoiding age-related failures. Rejuvenation effectively “refreshes” the system, helping to maintain its health over extended periods. Software systems often employ this technique to free up memory and reset internal counters.
8. Fault Tolerance in Cloud Computing
Virtual Machines
Switching gears, we find that cloud computing has its own set of fault-tolerant mechanisms. Virtual Machines (VMs) serve as an excellent example. In a cloud environment, VMs can be quickly spun up to replace failed instances, ensuring continued service availability. Moreover, VM snapshots can serve as quick rollback points, providing an extra layer of protection.
Microservices
Last but not least, microservices also play a pivotal role in cloud-based fault tolerance. These small, independent services form larger applications and can be individually scaled or replaced. Should one microservice fail, only that specific function of the application is affected. This isolation minimizes the blast radius of failures, making microservices a compelling model for fault-tolerant design in the cloud.
In summary, these diverse recovery techniques and cloud-specific mechanisms arm us with a potent arsenal for battling faults. They serve as linchpins that hold together our ever-complex, always-on digital world. Whether it’s through intelligent failover mechanisms, prudent checkpointing, or modern cloud architectures, fault tolerance remains an ever-evolving, indispensable field.
9. Case Studies
Google’s Google File System (GFS)
Initiating our examination of real-world applications, let’s focus first on Google’s Google File System (GFS). GFS is an emblematic case of a fault-tolerant, distributed file system designed to manage colossal data across thousands of machines. Confronted with hardware failures as an inevitable occurrence, GFS ingeniously leverages replication and chunking. Consequently, it assures data availability and integrity, even when individual nodes fail. Here, fault tolerance isn’t an add-on; it’s a foundational aspect of the architecture.
Amazon Web Services (AWS)
Transitioning to another industry titan, Amazon Web Services (AWS) offers a comprehensive suite of cloud computing services, all designed with fault tolerance in mind. Utilizing a multi-Availability Zone (AZ) model, AWS enables automatic failover across geographically separated data centers. Coupled with services like Amazon RDS and Elastic Load Balancing, AWS exemplifies best practices for building fault-tolerant, highly available systems. Thus, it stands as a vanguard in resilient cloud computing.
10. Conclusion
In culmination, the realm of fault tolerance is undeniably a linchpin in modern computing infrastructures. As we’ve traversed from its fundamental concepts to its sophisticated architectures, one point remains clear: fault tolerance is an imperative, not a luxury. Both Google’s GFS and Amazon’s AWS are living testaments to this, driving home the message that our ever-complex systems demand robust fault-tolerant mechanisms.
To that end, the techniques we’ve explored—failover, checkpointing, distributed systems, and more—form the bulwark against system failures. In summary, fault tolerance is the silent guardian that keeps our digital world spinning, and understanding its nuances is vital for anyone vested in technology’s present and future.
11. References
Books:
- “Fault-Tolerant Systems” by Israel Koren and C. Mani Krishna
- A comprehensive text covering the fundamentals of fault tolerance, design techniques, and examples of fault-tolerant systems in practice.
- “Reliable Computer Systems: Design and Evaluation” by Daniel P. Siewiorek and Robert S. Swarz
- Offers detailed coverage on the design, evaluation, and analysis of reliable and fault-tolerant computer systems.
- “Fault Tolerance: Principles and Practice” by Peter A. Lee and Thomas Anderson
- A primer on fault tolerance, this book discusses principles, techniques, and real-world applications, making it suitable for both students and professionals.
- “Dependable Computing for Critical Applications” edited by Algirdas Avižienis, Hermann Kopetz, and Janusz Laprie
- A collection of papers and essays on the theory and application of dependable and fault-tolerant computing.
RFCs:
- RFC 2022: “Support for Multicast over UNI 3.0/3.1 based ATM Networks”
- Discusses mechanisms to support fault tolerance in multicast over ATM networks, providing insights into early considerations for fault-tolerant networking.
- RFC 6378: “MPLS-TP Linear Protection”
- This RFC addresses fault management and protection switching in MPLS Transport Profile (MPLS-TP) networks, offering a protocol for enhancing network fault tolerance.
- RFC 4090: “Fast Reroute Extensions to RSVP-TE for LSP Tunnels”
- Focuses on mechanisms for achieving fast reroute in MPLS networks, a key aspect of fault tolerance by enabling quick recovery from failures.
- RFC 4427: “Recovery (Protection and Restoration) Terminology for Generalized Multi-Protocol Label Switching (GMPLS)”
- Provides terminology and concepts related to fault management and recovery in GMPLS, contributing to the understanding of fault tolerance in optical and packet networks.